UML类图
关联关系
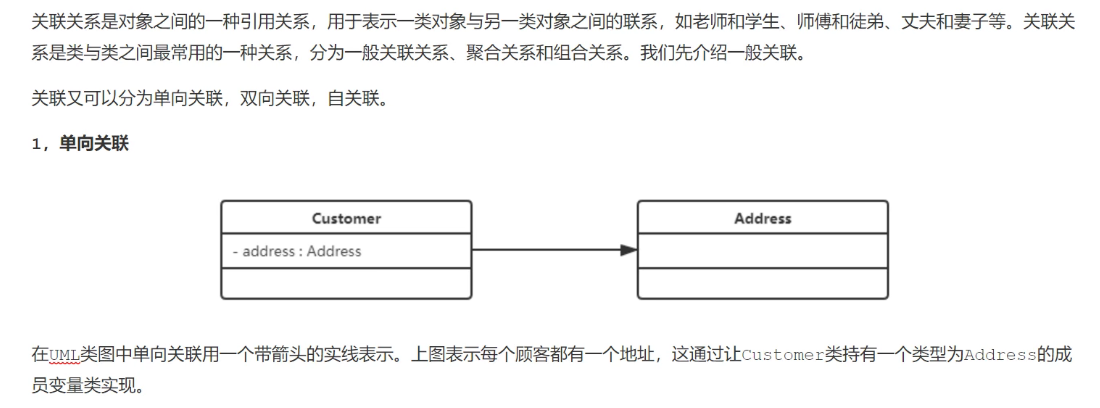
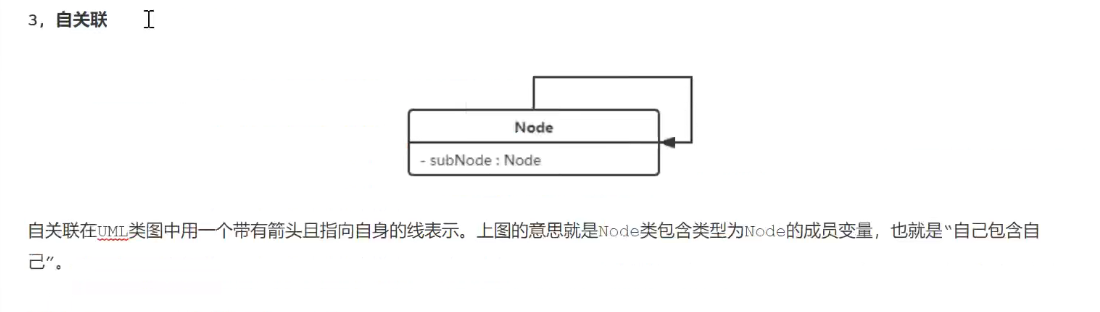
链表就是自关联
聚合关系
它是整体与部分的关系,且部分可以离开整体而单独存在。如车和轮胎是整体和部分的关系,轮胎离开车仍然可以存在。聚合关系是关联关系的一种,是强的关联关系;关联和聚合在语法上无法区分,必须考察具体的逻辑关系。
组合关系
它是整体与部分的关系,如没有公司就不存在部门。组合关系是关联关系的一种,是比聚合关系还要强的关系,它要求普通的聚合关系中代表整体的对象负责代表部分的对象的生命周期
依赖关系
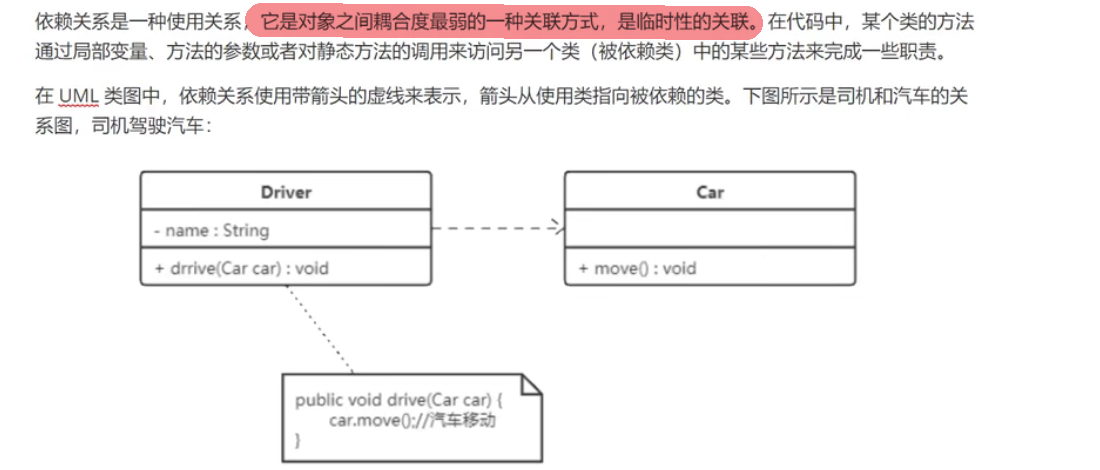
对于两个相对独立的对象,当一个对象负责构造另一个对象的实例,或者依赖另一个对象的服务时,这两个对象之间主要体现为依赖关系。
继承关系
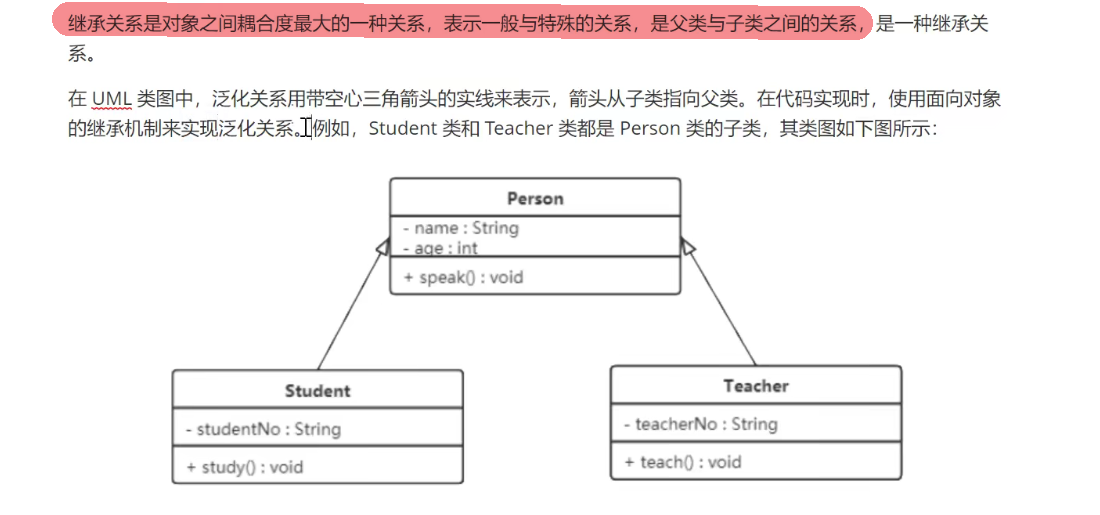
继承表示是一个类(称为子类、子接口)继承另外的一个类(称为父类、父接口)的功能,并可以增加它自己的新功能的能力。
实现关系
实现表示一个class类/struct结构体实现interface接口(可以是多个)的功能。
软件设计原则
在软件开发中,为了提高软件系统的可维护性和可复用性,增加软件的可扩展性和灵活性,程序员要尽量根据6条原则来开发程序,从而提高软件的开发效率、节约软件开发成本和维护成本。
开闭原则
对扩展开放,对修改关闭。
**在程序需要进行扩展的时候,**不能去修改原有的代码,实现一个热拔插的效果。简言之,是为了使程序扩展性好,易于维护和升级。
想要达到这样的效果,我们需要使用接口和抽象类(定义interface)。因为抽象灵活性好,实用性广,只要抽象的合理,可以基本保持软件架构的稳定。而软件中易变的细节可以在实现类中进行扩展,当软件需要发生变化时,只需要根据需求重新派生一个实现类来扩展就可以了。
总之就是定义接口声明通用的方法。当有新的需求时再次实现对应接口的方法即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
// 总结构体,也许有其他属性,不只是皮肤
type Sougou struct {
skin skinInterfaceI
// ...
}
// interface : 定义抽象接口
type skinInterfaceI interface {
disPlay()
}
type skinOne struct {
Name string
}
func (skin skinOne) disPlay() {
fmt.Println(skin.Name)
}
type skinTwo struct {
Name string
}
func (skin skinTwo) disPlay() {
fmt.Println(skin.Name)
}
func main() {
// 接口赋值为对应实现类,则可以调用对应实现类的方法细节
sougou := Sougou{
skin: skinOne{
Name: "one",
},
}
sougou.skin.disPlay()
}
|
里氏代换原则
里氏代换原则是面向对象设计的基本原则之一。
里氏代换原则:任何父类可以出现的地方,子类一定可以出现(即在代码中将父类替换为子类也可以输出预期的结果)。通俗理解:子类可以扩展父类的功能,但不能改变父类原有的功能。换句话说,子类继承父类时,除添加新的方法完成新增功能外,尽量不要重写父类的方法。只有不重写才能避免程序预期结果不对的可能性
如果通过重写父类的方法来完成新的功能,这样写起来虽然简单,但是整个继承体系的可复用性会比较差。抽象类的实现类完成的功能与原定功能不一样会导致读代码的时候对功能模糊。
golang中的重写与java不同,golang重写后父方法依然存在。且golang属于强类型语言,自己定义的结构体是无法直接转换成其他结构体的。
依赖倒置原则
依赖倒置原则的原始定义为:高层模块不应该依赖低层模块,两者都应该依赖其抽象;抽象不应该依赖细节,细节应该依赖抽象。其核心思想是:要面向接口编程,不要面向实现编程。
依赖倒置原则是实现开闭原则的重要途径之一,它降低了客户与实现模块之间的耦合。
由于在软件设计中,细节具有多变性,而抽象层则相对稳定,因此以抽象为基础搭建起来的架构要比以细节为基础搭建起来的架构要稳定得多。这里的抽象指的是接口或者抽象类,而细节是指具体的实现类。
使用接口或者抽象类的目的是制定好规范和契约,而不去涉及任何具体的操作,把展现细节的任务交给它们的实现类去完成。
多数情况下,这三个设计原则会同时出现,开闭原则是目标,里氏代换原则是基础,依赖倒转原则是手段,它们相辅相成,相互补充,目标一致。归根结底就是面向接口编程,上层依赖与接口,然后再传递具体的实现类来指明自己的身份
单一职责原则
又称单一功能原则,这里的职责是指类变化的原因,单一职责原则规定一个类应该有且仅有一个引起它变化的原因,否则类应该被拆分。
该原则提出对象不应该承担太多职责,如果一个对象承担了太多的职责,至少存在以下两个缺点:
- 一个职责的变化可能会削弱或者抑制这个类实现其他职责的能力;
- 当客户端需要该对象的某一个职责时,不得不将其他不需要的职责全都包含进来,从而造成冗余代码或代码的浪费。
单一职责原则的核心就是控制类的粒度大小、将对象解耦、提高其内聚性。如果遵循单一职责原则将有以下优点。
- 降低类的复杂度。一个类只负责一项职责,其逻辑肯定要比负责多项职责简单得多。
- 提高类的可读性。复杂性降低,自然其可读性会提高。
- 提高系统的可维护性。可读性提高,那自然更容易维护了。
- 变更引起的风险降低。变更是必然的,如果单一职责原则遵守得好,当修改一个功能时,可以显著降低对其他功能的影响
- 注意:单一职责同样也适用于方法。一个方法应该尽可能做好一件事情。如果一个方法处理的事情太多,其颗粒度会变得很粗,不利于重用
接口隔离原则
要求程序员尽量将臃肿庞大的接口拆分成更小的和更具体的接口,让接口中只包含客户感兴趣的方法。
客户端不应该被迫依赖于它不使用的方法。该原则还有另外一个定义:一个类对另一个类的依赖应该建立在最小的接口上(接口中不一定是只有一个方法,一定要适度)。
以上两个定义的含义是:要为各个类建立它们需要的专用接口,而不要试图去建立一个很庞大的接口供所有依赖它的类去调用。
接口隔离原则和单一职责都是为了提高类的内聚性、降低它们之间的耦合性,体现了封装的思想,但两者是不同的:
单一职责原则注重的是职责,而接口隔离原则注重的是对接口依赖的隔离。
单一职责原则主要是约束类,它针对的是程序中的实现和细节;接口隔离原则主要约束接口,主要针对抽象和程序整体框架的构建。
接口隔离原则是为了约束接口、降低类对接口的依赖性,遵循接口隔离原则有以下 5 个优点。
- 将臃肿庞大的接口分解为多个粒度小的接口,可以预防外来变更的扩散,提高系统的灵活性和可维护性。
- 接口隔离提高了系统的内聚性,减少了对外交互,降低了系统的耦合性。
- 如果接口的粒度大小定义合理,能够保证系统的稳定性;但是,如果定义过小,则会造成接口数量过多,使设计复杂化;如果定义太大,灵活性降低,无法提供定制服务,给整体项目带来无法预料的风险。
- 使用多个专门的接口还能够体现对象的层次,因为可以通过接口的继承,实现对总接口的定义。
- 能减少项目工程中的代码冗余。过大的大接口里面通常放置了许多不用的方法,那么当实现这个接口的时候,就会被迫实现冗余的无用代码。
迪米特法则
又叫作最少知识原则,迪米特法则的定义是:只与你的直接朋友交谈,不跟“陌生人”说话。其含义是:如果两个软件实体无须直接通信,那么就不应当发生直接的相互调用,可以通过第三方转发该调用。其目的是降低类之间的耦合度,提高模块的相对独立性。
迪米特法则中的“朋友”是指:当前对象本身、当前对象的成员对象、当前对象所创建的对象、当前对象的方法参数等,这些对象同当前对象存在关联、聚合或组合关系,可以直接访问这些对象的方法。
迪米特法则要求限制软件实体之间通信的宽度和深度,正确使用迪米特法则将有以下两个优点。
- 降低了类之间的耦合度,提高了模块的相对独立性。
- 由于亲合度降低,从而提高了类的可复用率和系统的扩展性。
但是,**过度使用迪米特法则会使系统产生大量的中介类,从而增加系统的复杂性,使模块之间的通信效率降低。**所以,在釆用迪米特法则时需要反复权衡,确保高内聚和低耦合的同时,保证系统的结构清晰。
合成复用原则
合成复用原则又叫组合/聚合复用原则。它要求在软件复用时,要尽量先使用组合或者聚合等关联关系来实现,其次才考虑使用继承关系来实现。
如果要使用继承关系,则必须严格遵循里氏替换原则。合成复用原则同里氏替换原则相辅相成的,两者都是开闭原则的具体实现规范。
通常类的复用分为继承复用和合成复用两种,继承复用虽然有简单和易实现的优点,但它也存在以下缺点。
- 继承复用破坏了类的封装性。因为继承会将父类的实现细节暴露给子类,父类对子类是透明的,所以这种复用又称为“白箱”复用(子类可以重写覆盖父类)。
- 子类与父类的耦合度高。父类的实现的任何改变都会导致子类的实现发生变化,这不利于类的扩展与维护。(只要父类的代码实现更改了一点都会给子类带来影响)
- 它限制了复用的灵活性。从父类继承而来的实现是静态的,在编译时已经定义,所以在运行时不可能发生变化(继承不能像接口一样形成多态,导致只能传一种对象)。
采用组合或聚合复用时,可以将已有对象纳入新对象中,使之成为新对象的一部分,新对象可以调用已有对象的功能(即结构体中包含结构体或接口),它有以下优点。
- 它维持了类的封装性。因为成分对象的内部细节是新对象看不见的,所以这种复用又称为“黑箱”复用。(只能进行调用,不能修改或覆盖成员结构体或接口的实现细节)
- 新旧类之间的耦合度低。这种复用所需的依赖较少,新对象存取成分对象的唯一方法是通过成分对象的接口。
- 复用的灵活性高。这种复用可以在运行时动态进行,新对象可以动态地引用与成分对象类型相同的对象。(只有在运行时才会去调用对应结构体或接口的方法,且如果是接口可以实现多态,即传不同的结构体有不同的实现细节和不同的方法)
创建者模式(5种)
用于描述“怎样创建对象”,它的主要特点是“将对象结构体的创建与使用分离”。
创建者模式的主要关注点是怎样创建对象,它的主要特点是将对象的创建与使用分离。
这样可以降低系统的耦合度,使用者不需要关注对象的创建细节。
单例模式、工厂方法模式、抽象工厂模式、原型模式、建造者模式
单例设计模式(系统中仅有一个该类对象,其他地方通过调用这个对象暴露的方法获取它的指针进行使用,它可以在系统启动时生成,也可以在第一次调用时生成,即饿汉式和懒汉式)
这种类型的设计模式属于创建者模式,它提供了一种创建对象的最佳方式。
这种模式涉及到一个单一的类(仅一个结构体),并且确保只有单个对象被创建。这个类提供了一种访问其唯一对象的方式(get方法,直接获取指针),外部不需要实例化该类的对象。
它只有一个实例,自我实例化并提供全局访问点
1
2
3
|
单例设计模式分为两种:
饿汉式:类加载就会导致该单实例对象被创建
懒汉式:类加载不会导致该单实例对象被创建,而是首次使用该对象时才会创建
|
饿汉式:
1
2
3
4
5
6
7
8
9
|
type singleton struct{}
// 定义一个私有的变量
var ins *singleton = &singleton{}
// 通过函数返回它的指针
func GetSingleton() *singleton {
return ins
}
|
这种方法的缺点是如果singleton创建初始化比较复杂耗时时,加载时间会延长。如果声明后并没有调用过Get方法,那么这个资源就会造成内存浪费。
懒汉式:
1
2
3
4
5
6
7
8
9
10
|
// 定义一个私有的变量
var ins *singleton
// 通过函数返回它的指针
func GetSingleton() *singleton {
if ins == nil {
ins = &singleton{}
}
return ins
}
|
但是这种模式最大的缺点是非线程安全的,当正在创建时,有线程来访问此时ins = nil就会再创建,单例类就会有多个实例了,可以通过加锁(不能通过读写锁,可能会导致部分获取到的是nil,要更严格的锁才行)或者通过sync.Once来实现线程安全
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// 1.在外部加锁虽然解决并发的问题,但会导致代码从并发变为串行
mu.Lock()
defer mu.Unlock()
// 2.双重锁,如果不为空就不加锁,避免每次加锁,提高代码效率
// 如果有多个线程同时通过第一层判断,他们会竞争锁,最终依然只有一个加锁成功,
// 然后进入第二层判断进行赋值,当时间片轮转到其他当初竞争锁的线程时,
// 虽然它会进行加锁,但是它第二层判断会发现ins已经不为空了,直接跳出判断
if ins == nil {
mu.Lock()
defer mu.Unlock()
if ins == nil {
ins = &singleton{}
return ins
}
}
// 3.sync.Once实现
once.Do(func() {
ins = &singleton{}
})
|
工厂方法设计模式(设定一个工厂,每调用一个它的方法,则会给我们返回一个相应的对象,每个人调用此方法返回的对象都是相同属性的不同对象,避免每次用new生成时,如果原结构体改变,则系统中每个地方的生成都需要修改,实现解耦)
在java中万物皆对象,golang也类似。要使用时都需要进行创建,但如果创建的时候直接new该对象,就会对该对象耦合严重,假如我们要更换对象(如对象改名,新增一个对象作为该对象的另一种选择),所有new对象的地方都需要修改一遍,这显然违背了软件设计的开闭原则。但如果使用工厂来生产对象,那么我们就只需要和工厂这一个对象进行打交道,彻底和对象解耦,如果要修改对象,直接在工厂里更换该对象即可,达到了与对象解耦的目的。即工厂模式最大的优点就是解耦
工厂可以把创建和使用分开,分别存放,修改工厂代码时不必修改和重新编译使用的代码
简单工厂模式
简单工厂不是一种设计模式,反而比较像一种编程习惯
它包含如下角色:
- 抽象产品:定义了产品规范,描述了产品的主要特性和功能。
- 具体产品:实现或者继承抽象产品的子类。
- 具体工厂:提供了创建产品的方法,调用者通过该方法来获取产品。
如咖啡、咖啡工厂、咖啡店、拿铁咖啡和美式咖啡的关系,工厂来处理创建对象的细节(是拿铁还是美式),而咖啡店作为工厂的客户,后期需要咖啡对象直接从工厂中获得即可。不需要每次点单都要在自己的代码中new一个新的,因为客户可能有很多个,如果新增了一款咖啡,那么每个客户端都要增加new新咖啡的代码,而使用简单工厂模式的话则只需要修改工厂模式的代码即可。
简单工厂模式虽然解除了咖啡店和具体咖啡的耦合,但是又产生了咖啡店和咖啡工厂的耦合,咖啡工厂和具体咖啡的耦合,依然违反了开闭原则,但是这种只修改一处代码的情况总比修改客户端多处代码的情况要好解决。
总结:简单工厂模式封装了创建对象的过程,可以通过参数直接获取对象。把对象的创建和业务逻辑层分开,这样以后就避免了修改客户端代码,如果要实现新的产品直接修改工厂类而不需要在原代码中修改,这样就降低了在客户代码修改的可能性,更容易扩展,但是增加新产品时还是需要修改工厂类代码,违背的开闭原则。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
// 工厂, 用一个函数来作为工厂给外部提供服务传递对象;也可以定义一个工厂空结构体,它的方法是创建对应具体实例
func CooferFactory(types string) (coffer pkg.Coffer) {
switch types {
case "late":
coffer = pkg.LateCoffer{
Name: "late",
}
case "amera":
coffer = pkg.AmercaCoffer{
Name: "amera",
}
default:
panic("input error")
}
return coffer
}
// 咖啡店,根据关键字不同定义不同的咖啡
func CofferStore() {
coffers := CooferFactory("late")
fmt.Println(coffers.GetName())
}
// 咖啡接口,有getName接口,用接口作为父类,抽取两种咖啡都有的方法
type Coffer interface {
GetName() string
}
// 拿铁咖啡和美式咖啡,咖啡的子类
type LateCoffer struct {
Name string
}
func (l LateCoffer) GetName() string {
return l.Name
}
type AmercaCoffer struct {
Name string
}
func (a AmercaCoffer) GetName() string {
return a.Name
}
|
当在代码里看到switch的时候,就可以思考是否能用简单工厂模式。它可以避免修改多处地方代码。
工厂方法模式
针对简单工厂设计模式的缺点,使用工厂方法模式就可以完美的解决问题,完全遵循开闭原则。
它的核心思想就是会定义一个创建对象的接口,让子类决定实例化哪个产品类对象。工厂方法使一个产品类的实例化延迟到其工厂的子类
它包含如下角色:
- 抽象工厂:提供了创建产品的接口,调用者通过它访问具体工厂的工厂方法来创建产品。
- 具体工厂:主要是实现抽象工厂接口中的抽象方法,完成具体产品的创建
- 抽象产品:定义了产品规范,描述了产品的主要特性和功能。
- 具体产品:实现了抽象产品角色所定义的接口,由具体工厂来创建,它同具体工厂之间一一对应
这种设计方式会出现多个具体工厂来一一对应具体产品,这样的话如果新增了产品,只需要生产一个具体的工厂和具体产品即可,不会修改原先的代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
// 抽象工厂
type Factory interface {
CreateCoffer() Coffer
}
// 实体工厂
type AmercaFactory struct {
}
func (a AmercaFactory) CreateCoffer() Coffer {
return AmercaCoffer{
Name: "amerca",
}
}
type LateFactory struct {
}
func (l LateFactory) CreateCoffer() Coffer {
return LateCoffer{
Name: "late",
}
}
// 咖啡店,根据关键字不同定义不同的咖啡
func CofferStore() {
var factory pkg.Factory = pkg.LateFactory{}
fmt.Println(factory.CreateCoffer().GetName())
}
|
它就比简单工厂模式多了一个抽象工厂接口,咖啡店不需要用关键字来判断是否是哪种咖啡,只需要给抽象工厂变量赋值上具体的那个工厂,它就会生产对应的咖啡,新增咖啡种类也只需要继承抽象工厂,重新定义一个具体工厂和具体产品即可,不需要修改工厂类的代码了。
优缺点:
- 用户只需要知道具体工厂的名称就可以得到所要的产品,无序知道产品的具体创建过程。
- 在系统增加新的产品时只需要增加具体产品类和对应的具体工厂类,无须对原工厂进行任何修改,满足开闭原则。
- 但是它的缺点也同样明显,每增加一个产品就必须要增加一个产品类和工厂类,这增加了系统的复杂度。
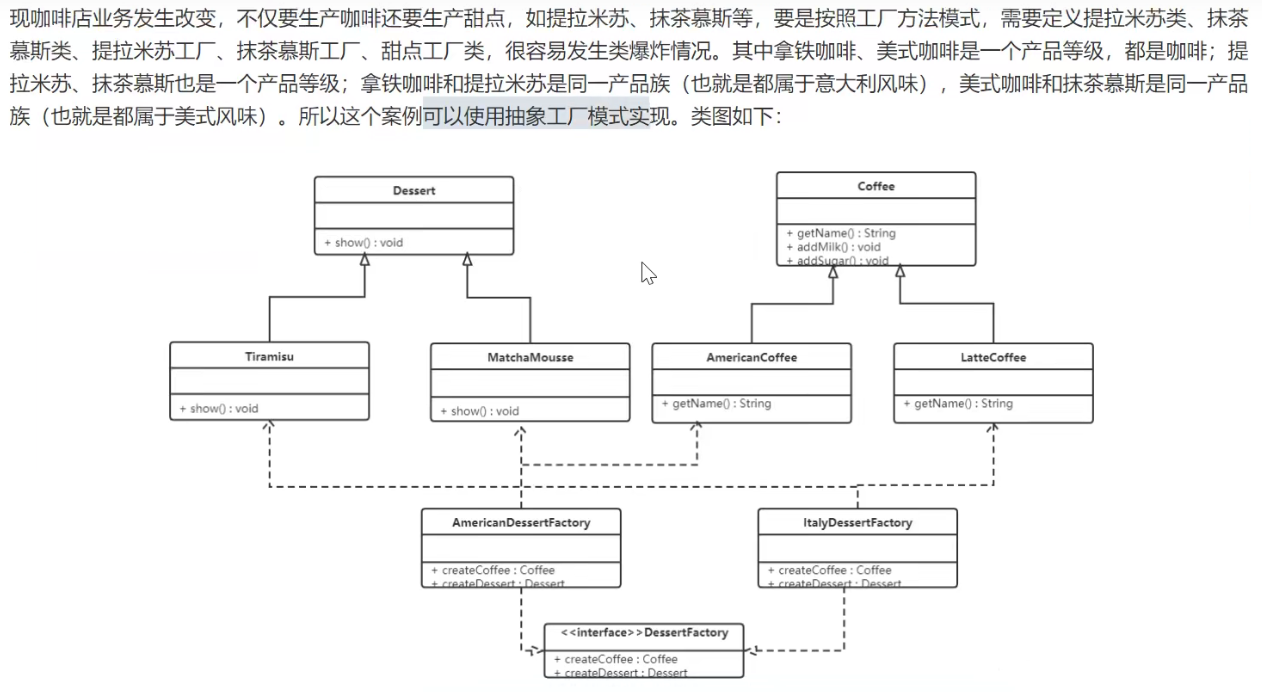
抽象工厂模式(通过选择不同的工厂来生成同一产品族的产品,它能保证客户端始终只使用同一个产品族中的对象)

它是一种为访问类提供一个创建一组相关或相互依赖对象的接口(同一产品族),且访问类无须指定所要产品的具体类就能得到同族的不同等级的产品的模式结构。
抽象工厂模式是工厂方法模式的升级版本,工厂方法模式只生产一个等级的产品,而抽象工厂模式可生产多个等级的产品。
它包含如下角色:
- 抽象工厂:提供了创建产品的接口,它包含多个创建产品的方法,可以创建多个不同等级的产品。
- 具体工厂:主要是实现抽象工厂接口中的多个抽象方法,完成具体产品的创建
- 抽象产品:定义了产品规范,描述了产品的主要特性和功能,抽象工厂模式有多个抽象产品。
- 具体产品:实现了抽象产品角色所定义的接口,由具体工厂来创建,它同具体工厂之间是多对一的关系,一个工厂可以生产不同的产品
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
|
interface总工厂:
// DessertFactory 甜品总工厂,生产咖啡和甜品
type DessertFactory interface {
CreateCoffer() Coffer
CreateDessert() Dessert
}
// 咖啡接口,不同产品族但性质相同的东西
type Coffer interface {
GetName() string
}
// 甜品接口
type Dessert interface {
Show() string
}
具体产品族的factory实体工厂:
type AmercaFactory struct {
}
func (a AmercaFactory) CreateCoffer() Coffer {
return AmercaCoffer{
Name: "AmercaCoffer",
}
}
func (a AmercaFactory) CreateDessert() Dessert {
return MatchaMousse{
Name: "MatchaMousse",
}
}
type ItalyFactory struct {
}
func (a ItalyFactory) CreateCoffer() Coffer {
return LateCoffer{
Name: "LateCoffer",
}
}
func (a ItalyFactory) CreateDessert() Dessert {
return Tiramisu{
Name: "Tiramisu",
}
}
具体产品:
// 拿铁咖啡和美式咖啡
type LateCoffer struct {
Name string
}
func (l LateCoffer) GetName() string {
fmt.Println("我是LateCoffer")
return l.Name
}
type AmercaCoffer struct {
Name string
}
func (a AmercaCoffer) GetName() string {
fmt.Println("我是AmercaCoffer")
return a.Name
}
// 拿铁咖啡和美式咖啡
type Tiramisu struct {
Name string
}
func (t Tiramisu) Show() string {
fmt.Println("提拉米苏")
return t.Name
}
type MatchaMousse struct {
Name string
}
func (a MatchaMousse) Show() string {
fmt.Println("抹茶慕斯")
return a.Name
}
main:
var factory pkg.DessertFactory
func main() {
// 通过定义不同的产品族工厂来生产不同类型的产品
factory = pkg.ItalyFactory{}
coffer := factory.CreateCoffer()
fmt.Println(coffer.GetName())
d := factory.CreateDessert()
fmt.Println(d.Show())
}
|
如果要再加一个产品族的话,只需要加一个对应的实体工厂和具体产品即可,不需要修改其他的类。满足开闭原则
优缺点:
- 当一个产品族中的多个对象被设计成一起工作时,它能保证客户端始终只使用同一个产品族中的对象。(类似于分组,客户端只能使用这一个分组中的对象,另一个分组的无法使用)
- 但是当一个产品族需要新增一个产品时,所有的工厂类都需要进行修改。因为新增一个产品就意味着总接口需要定义生产这个产品的方法,而实体工厂结构体必须要实现总工厂接口的所有方法才算继承,那么所有实体工厂类都需要进行更改。
使用场景:
- 当需要创建的对象是一系列相互关联或相互依赖的产品族时。
- 系统中有多个产品族,但每次只使用其中的某一族产品(分组)。
- 系统中提供了产品的类库,且所有产品的接口相同,客户端不依赖产品实例的创建细节和内部结构。
如输入法换皮肤是一整套一起换(logo、背景、输入框等全部一起换)
原型模式(本质就是复制一个已经存在的对象来生成新对象,当某个对象生成较为复杂,比如有很多参数,并且该对象的不同实例差别也就是一两个参数不同,就可以使用该模式简化生成流程)
用一个已经创建的实例作为原型,通过复制该原型对象来创建一个和原型对象相同的新对象。
原型模式包含如下角色:
- 抽象原型类:规定了具体原型对象必须实现的clone()方法。
- 具体原型类:实现抽象原型类的clone()方法,它是可被复制的对象。
- 访问类:使用具体原型中的clone()方法来复制新的对象
原型模式的克隆分为浅克隆和深克隆。
浅克隆:创建一个新对象,新对象的属性和原来对象完全相同,对于非基本类型属性,仍指向原有属性所指向的对象的内存地址(采用引用存储指针)。浅克隆是指拷贝对象时仅仅拷贝对象本身(包括对象中的基本变量),而不拷贝对象包含的引用指向的对象,只是指向原对象引用对象的指针
深克隆:创建一个新对象,属性中引用的其他对象也会被克隆,不再指向原有对象地址。
在golang中,由于结构体在函数之间的传递属于值传递,因此大部分情况下都是深克隆,如果要使用浅克隆则需要特殊对待。
用原型模式生成“三好学生”奖状:
同一学习的三好学生奖状除了获奖人姓名不同,其他都相同,可以使用原型模式复制多个奖状出来,然后修改奖状上的姓名即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
//抽象原型类
type Cloneable interface {
Clone() Cloneable
SetName(name string)
GetName() string
}
// 实体原型类
type Citation struct {
Name string
}
func (c *Citation) Clone() Cloneable {
fmt.Println("克隆成功")
return &Citation{
Name: c.Name,
}
}
func (c *Citation) SetName(name string) {
c.Name = name
}
func (c *Citation) GetName() string {
return c.Name
}
// 访问
var role pkg.Cloneable
func main() {
role = &pkg.Citation{}
cloable1 := role.Clone()
cloable1.SetName("张三")
cloable2 := role.Clone()
cloable2.SetName("李四")
fmt.Println(cloable1)
fmt.Println(cloable2)
}
|
使用场景:
- 对象的创建非常复杂,有很多个属性且需要对某些属性进行加工,则可以通过原型模式快捷的创建对象,通过clone就不需要再考虑创建的细节
- 性能和安全要求比较高,创建细节由一个模板生成,可以避免创建的时候发生遗漏造成空指针等问题
但是每种具体实现类型都要有一个克隆自己的操作。在某些场景会比较困难。
建造者模式(针对一个复杂对象的创建,将它的元素作为配件进行组装,不同的组装顺序或配件内容不同都会形成不同的结构体,我们只需要通过builder来选择组装哪种结构体即可,结构体的具体数据赋值都由具体建造者实现了,简化初始化赋值流程,有新的类型再实现一个具体建造者即可。工厂模式是生成同一种类型的对象,建造者模式是生成不同类型的对象,但结构体必须是同一个结构体,只是不同的属性)
将一个复杂对象的构建与表示分离,使得同样的构建过程可以创建不同的表示。
- 分离了部件的构造(由Builder角色负责)和装配(由Director角色负责)。从而可以构造出复杂的对象。这个模式适用于某个对象的构建过程复杂的情况
- 由于实现了构建和装配的解耦。不同的构建,相同的装配也可以做出不同的对象;相同的构建,不同的装配顺序也可以做出不同的对象。也就是实现了构建算法、装配算法的解耦,实现了更好的复用。如组装台式机,不同型号的设备可以搭配出不同的主机。
- 建造者模式可以将部件和其组装过程分开,一步步创建一个复杂的对象。用户只需要指定复杂对象的类型就可以得到该对象,无须知道其内部的具体构造细节。
- 但是这个模式缺点就是所有产品的组成部分必须相同(因为只能对一个结构体进行组装),这限制了其使用范围。且如果产品内部发生变化,则建造者也要同步修改,指挥者也要新增组装方法,后期维护成本较大。
建造者模式包含如下角色:
- 抽象建造者类:这个接口规定要实现复杂对象的哪些部分的创建,并不涉及具体的对象部件的创建。
- 具体建造者类:实现抽象建造者接口,完成复杂产品的各个部件的具体创建方法。在构造过程完成后,提供产品的实例。(这里重点不是部件的创建,它强调的是装配的过程。创建可以用其他创建者模式来获取)
- 产品类:要创建的复杂对象。
- 指挥者类:调用具体建造者来创建复杂对象的各个部分,在指导者中不涉及具体产品的信息,只负责保证对象各部分完整创建或按某种顺序创建。
指挥者用来指挥建造顺序,建造者只管造部件
如生产共享单车
生产自行车是一个复杂的过程,它包含了车架、车座等组件的生产。而车架又有碳钎维、铝合金等材质的,车座有橡胶、真皮等材质。对于自行车的生产就可以使用建造者模式
产品角色(Product):
1
2
3
4
5
6
7
8
9
10
11
12
|
// 这里为了方便使用的基本类型,但是建造者模式通常成员是复杂类型
type Bike struct {
frame string // 车架
seat string // 车座
}
func (b *Bike) SetFrame(frame string) {
b.frame = frame
}
func (b *Bike) SetSeat(seat string) {
b.seat = seat
}
|
抽象建造者(Abstract Builder)
1
2
3
4
5
6
|
type BuilderBike interface {
BuildFrame() //构建车架
BuildSeat() //构建车座
CreateBike() //创建自行车
GetResult() interface{} // 获取结果
}
|
具体建造者(Concrete Builder)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
type MobikeBuilder struct {
Bike *Bike
}
func (m *MobikeBuilder) BuildFrame() {
m.Bike.SetFrame("碳钎维的车架")
}
func (m *MobikeBuilder) BuildSeat() {
m.Bike.SetSeat("橡胶车座")
}
func (m *MobikeBuilder) CreateBike() {
fmt.Println("新建一个摩拜单车")
m.Bike = new(Bike)
}
func (m *MobikeBuilder) GetResult() interface{} {
return m.Bike
}
type OfoBuilder struct {
Bike *Bike
}
func (o *OfoBuilder) BuildFrame() {
o.Bike.SetFrame("铝合金的车架")
}
func (o *OfoBuilder) BuildSeat() {
o.Bike.SetSeat("真皮车座")
}
func (o *OfoBuilder) CreateBike() {
fmt.Println("新建一个ofo单车")
o.Bike = new(Bike)
}
func (o *OfoBuilder) GetResult() interface{} {
return o.Bike
}
|
指挥者(Director)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
// 指挥者
type Director struct {
builder BuilderBike
}
// 设置构建者,选择某种构建顺序
func (d *Director) SetBuilder(builder BuilderBike) {
d.builder = builder
}
// 可以创建多个Generate来构建成员变量不同的Bike
func (d *Director) Generate() *Bike {
d.builder.CreateBike()
d.builder.BuildSeat()
d.builder.BuildFrame()
// interface转为指定类型
return d.builder.GetResult().(*Bike)
}
|
main.go :
1
2
3
4
5
6
7
8
|
// 创建一个指挥者
director := new(pkg.Director)
// 选定制造哪种车
builder := new(pkg.OfoBuilder)
director.SetBuilder(builder)
// 根据某顺序进行组装
bike := director.Generate()
fmt.Println(bike)
|
建造者模式唯一区别于工厂模式的是针对复杂对象的创建。也就是说,如果创建简单对象,通常都是使用工厂模式进行创建,而如果创建复杂对象,就可以考虑使用建造者模式。当需要创建的产品具备复杂创建过程时,可以抽取出相共性创建过程,然后交由具体实现类来自定义创建流程,使得同样的创建行为可以生产出不同的产品,分离了创建与表示,使创建产品的灵活性大大增加。
建造者模式主要适用于以下应用场景:
- 相同的方法,不同的执行顺序,产生不同的结果。
- 多个部件或零件,都可以装配到一个对象中,但是产生的结果又不相同。
- 产品类非常复杂,或者产品类中不同的调用顺序产生不同的作用。
- 初始化一个对象特别复杂,参数多,而且很多参数都具有默认值。
建造者(Builder)模式在应用过程中可以根据需要改变,如果创建的产品种类只有一种,只需要一个具体建造者,这时可以省略掉抽象建造者,甚至可以省略掉指挥者角色。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
type MobikeBuilder struct {
Bike *Bike
}
func (m *MobikeBuilder) BuildFrame() *MobikeBuilder {
m.Bike.SetFrame("碳钎维的车架")
return m
}
func (m *MobikeBuilder) BuildSeat() *MobikeBuilder {
m.Bike.SetSeat("橡胶车座")
return m
}
func (m *MobikeBuilder) CreateBike() *MobikeBuilder {
fmt.Println("新建一个摩拜单车")
m.Bike = new(Bike)
return m
}
func (m *MobikeBuilder) GetResult() interface{} {
return m.Bike
}
type OfoBuilder struct {
Bike *Bike
}
func (o *OfoBuilder) BuildFrame() *OfoBuilder {
o.Bike.SetFrame("铝合金的车架")
return o
}
func (o *OfoBuilder) BuildSeat() *OfoBuilder {
o.Bike.SetSeat("真皮车座")
return o
}
func (o *OfoBuilder) CreateBike() *OfoBuilder {
fmt.Println("新建一个ofo单车")
o.Bike = new(Bike)
return o
}
func (o *OfoBuilder) GetResult() interface{} {
return o.Bike
}
main.go:
// builder := new(pkg.OfoBuilder)
builder := new(pkg.MobikeBuilder)
mobikeBike := builder.CreateBike().BuildFrame().BuildSeat().GetResult().(*pkg.Bike)
|
这种省略掉抽象建造者和指挥者的模式是将构建顺序交给了调用端来定,舍弃了指挥者,实现链式编程,提高可读性。甚至可以在build中通过方法传参实现同一个build构建不同类型不同顺序的结构体
如果希望屏蔽对象的创建过程,只提供一个封装良好的对象,则可以选择工厂方法模式。而建造者模式可以用在复杂产品的组装方面,如通过装配不同的组件或者相同组件的不同顺序,可以产生出一个新的对象,它可以产生一个非常灵活的架构,方便地扩展和维护系统。两者都是创建一个产品,但工厂模式关心整体,建造者模式关心细节。
结构型模式(7种)
结构型模式描述如何将类或对象按某种布局组成更大的结构。它分为类结构型模式和对象结构型模式,前者采用继承机制来组织接口和类,后者采用组合或聚合来组合对象。
由于组合关系或聚合关系比继承关系耦合度低,满足“合成复用原则”,所以对象结构型模式比类结构型模式具有更大的灵活性。
代理模式(在调用者和目标对象中插入一个代理对象,由它去调用目标对象的方法,保护目标对象,并对目标对象的功能进行增强)
由于某些原因需要给某对象提供一个代理(中介)以控制该对象的访问。此时访问对象不适合或者不能直接引用目标对象,代理对象作为访问对象和目标对象之间的中介。
代理按照生成时机不同又分为静态代理和动态代理。静态代理在编译时期就生成,而动态代理则是运行时动态生成。
代理模式分为三种角色:
- 抽象主题类:通过接口或抽象类声明真实主题和代理对象要实现的业务方法(规范)。
- 真实主题类:实现了抽象主题中的具体业务,是代理对象所代表的真实对象,是最终要引用的对象。
- 代理类:提供了与真实主题相同的接口,其内部含有对真实主题的引用,它可以访问、控制或扩展真实主题的功能(一个代理类可以同时代理多个目标对象,如一个地方商可以代理多家厂商)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
抽象主题类:
type Computers interface {
// 售卖电脑
SellComputers()
}
真实主题类:
// 联想电脑
type Lenovo struct{}
func (l Lenovo) SellComputers() {
fmt.Println("出售了一台联想电脑")
}
// 戴尔电脑
type Dell struct{}
func (d Dell) SellComputers() {
fmt.Println("出售了一台戴尔电脑")
}
代理类:
// 代理商
type ComputerProxy struct {
Computers
}
// 可以对真实主题的参数、方法体、返回值等进行增强
func (c ComputerProxy) SellComputers() {
fmt.Println("收取了手续费")
c.Computers.SellComputers()
}
main.go:
// 静态代理
var (
Lenovo = new(pkg.Lenovo)
Dell = new(pkg.Dell)
)
func main() {
ComputerProxy := new(pkg.ComputerProxy)
ComputerProxy.Computers = Dell
ComputerProxy.SellComputers()
}
|
一般来说,Go 这种纯静态的编译型语言,想实现像 Spring 那样的动态代理基本上是不可能实现的。动态代理就是在最开始不存在代理者,是在运行时动态生成的,并且一个代理可以代理一个接口的所有方法,摆脱了繁杂的重复工作。Go如果想使用动态代理就需要使用第三方包,并且大多数情况下得不偿失,而且绝大多数情况,我觉得业务代码是不需要动态代理能力的。
动态代理和静态代理相比较最大的好处就是接口声明的所有方法都被转移到代理类一个集中的方法中处理(InvocationHandler.invoke)。这样,在接口方法数量比较多的时候,我们可以灵活处理,而不需要像静态代理那样对每一个方法进行中转,接口中新增一个方法,代理类也得实现对应的方法。
如果接口增加一个方法,静态处理模式除了所有实现类需要实现这个方法外,所有代理类也需要实现此方法。增加了代码维护的复杂度,而动态代理不会出现该问题。动态代理将其全部集中处理,如果增强方式不一样就根据方法名字判断增强。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
Java代码:
// 动态代理必须继承InvocationHandler
public class DynProxyLawyer implements InvocationHandler {
// 可以动态指定不同的接口,减少代码量
private Object target;//被代理的对象
public DynProxyLawyer(Object obj){
this.target=obj;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("案件进展:"+method.getName());
Object result=method.invoke(target,args);
return result;
}
}
public class ProxyFactory {
public static Object getDynProxy(Object target) {
InvocationHandler handler = new DynProxyLawyer(target);
return Proxy.newProxyInstance(target.getClass().getClassLoader(), target.getClass().getInterfaces(), handler);
}
}
https://www.bilibili.com/video/BV1Np4y1z7BU?p=58
|
优缺点:
- 代理模式在客户端与目标对象之间起到一个中介作用和保护目标对象的作用(客户端不直接访问目标对象);
- 代理对象可以扩展目标对象的功能;
- 代理模式能将客户端与目标对象分离,在一定程度上降低了系统的耦合度;
- 缺点就是增加了系统的复杂度;
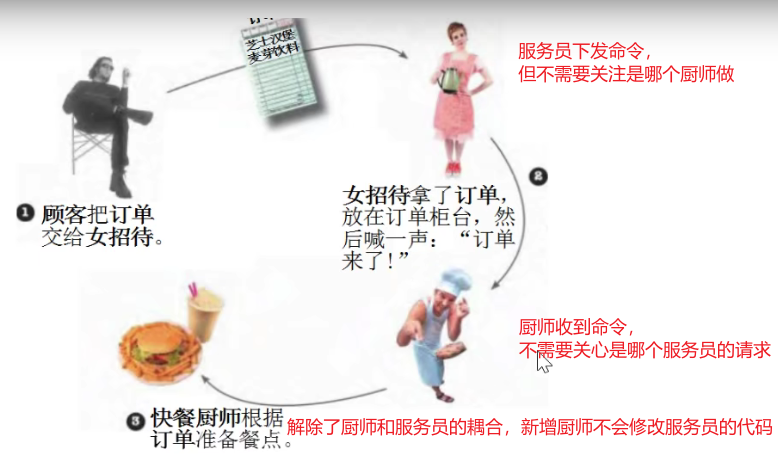
适配器模式(调用者无法调用原有的接口,则新增一个接口,让它去调用原有接口,调用者调用这个新接口,如调用第三方组件,结果自己定义的接口和第三方组件的接口对不上,则可以采用此模式,但是遇到这种情况更建议重构代码)
将一个类的接口转换成客户希望的另一个接口,使得原本由于接口不兼容而不能一起工作的那些类能一起工作。
适配器模式分为类适配器模式和对象适配器模式,前者类之间的耦合度比后者高(因为是通过继承实现),且要求程序员了解现有组件库中的相关部件的内部结构,所以应用相对较少些。
适配器模式包含以下主要角色:
- 目标接口:当前系统业务所期待的接口,它可以是抽象类或接口。
- 适配者类:它是被访问和适配的现存组件库中的组件接口(项目中的现有接口)
- 适配器者类:它是一个转换器,通过继承或引用适配者的对象,把适配者接口转换成目标接口,让客户按目标接口的格式访问适配者。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
// TF卡,适配者接口ITarget
type TFCardI interface {
ReadTF()
WriteTF()
}
type TFCard struct {
}
func (t TFCard) ReadTF() {
fmt.Println("read TF")
}
// SD卡 ,目标接口Adaptee
type SDCardI interface {
ReadSD()
WriteSD()
}
type SDCard struct {
}
func (s SDCard) ReadSD() {
fmt.Println("read SD")
}
// 适配器接口Adapter
type SDAdapterTF struct {
TFCard TFCard
}
// 适配器在方法内调用另一个接口或结构体的方法
func (sd SDAdapterTF) ReadSD() {
sd.TFCard.ReadTF()
}
main.go:
sdAdapterTF := pkg.SDAdapterTF{
TFCard: pkg.TFCard{},
}
// 适配器和目标结构体实现了同一个接口
// 表面是调用的readSD,但是本质上调用的是readTF
sdAdapterTF.ReadSD()
|
应用场景:
- 以前开发的系统存在满足新系统功能需求的类,但其接口同新系统的接口不一致
- 使用第三方提供的组件,但组件接口定义的和自己要求的接口定义不同
- 即代理模式是扩展接口,适配器模式是改变接口且符合开闭原则
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
package adaptor
import "fmt"
// 我们的接口(新接口)——音乐播放
type MusicPlayer interface {
play(fileType string, fileName string)
}
// 在网上找的已实现好的库 音乐播放
// ( 旧接口)
type ExistPlayer struct {
}
func (*ExistPlayer) playMp3(fileName string) {
fmt.Println("play mp3 :", fileName)
}
func (*ExistPlayer) playWma(fileName string) {
fmt.Println("play wma :", fileName)
}
// 适配器
type PlayerAdaptor struct {
// 持有一个旧接口
existPlayer ExistPlayer
}
// 实现新接口
func (player *PlayerAdaptor) play(fileType string, fileName string) {
switch fileType {
case "mp3":
player.existPlayer.playMp3(fileName)
case "wma":
player.existPlayer.playWma(fileName)
default:
fmt.Println("暂时不支持此类型文件播放")
}
}
|
优点
- 可以让两个没有关联的类一起运行。
- 提高了类的复用
- 灵活性好,符合开闭原则
缺点
- 过多地使用适配器,会让系统非常零乱,不易整体进行把握。比如,明明看到调用的是 A 接口,其实内部被适配成了 B 接口的实现,一个系统如果太多出现这种情况,无异于一场灾难,增加了代码阅读难度。因此如果不是很有必要,可以不使用适配器,而是直接对系统进行重构。
装饰者模式(可以动态给某个对象加职责,不加也不会影响程序的运行。如一碗面我想加鸡蛋加培根等则可以用这种方法,它将原始对象作为一个参数或变量传给装饰者类,装饰者类和原始对象都实现的同一个接口)
在不改变现有对象结构的情况下,动态的给该对象增加一些职责(即增加其额外功能)的模式。
装饰者(Decorator)模式中的角色:
- 抽象构件角色:定义一个抽象接口以规范准备接受附加责任的对象。
- 具体构件角色:实现抽象构建,通过装饰角色为其添加一些职责。
- #抽象装饰角色:继承或实现抽象构建,并包含具体构建的实例,可以通过其子类扩展具体构件的功能(只存在于JAVA,GOLANG没有这个角色,因为装饰和构件要实现同一个接口才能一直嵌套装饰下去,JAVA可以通过继承,但golang没有继承,分开就只能装饰一次,不能嵌套)
- 具体装饰角色:实现抽象装饰的相关方法,并给具体构件对象添加附加的责任。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
// 规范面条的方法,抽象构件角色
type Noddles interface {
GetDescription() string // 描述
GetPrice() float32 //价格
}
// 拉面,具体构件角色
type Ramen struct {
Name string
Price float32
}
func (r Ramen) GetDescription() string {
return r.Name
}
func (r Ramen) GetPrice() float32 {
return r.Price
}
// 炒饭
type FriedRice struct {
Name string
Price float32
}
func (r FriedRice) GetDescription() string {
return r.Name
}
func (r FriedRice) GetPrice() float32 {
return r.Price
}
// 加蛋,具体装饰角色。如果分开实现接口,Noddles在第二次就无法获取到
type Egg struct {
Noddles Noddles
Name string
Price float32
}
func (e *Egg) SetNoddles(n Noddles) {
e.Noddles = n
}
func (e *Egg) GetDescription() string {
return e.Name + "-" + e.Noddles.GetDescription()
}
func (e *Egg) GetPrice() float32 {
return e.Price + e.Noddles.GetPrice()
}
// 加培根,具体装饰角色
type Bacon struct {
Noddles Noddles
Name string
Price float32
}
func (e *Bacon) SetNoddles(n Noddles) {
e.Noddles = n
}
func (e *Bacon) GetDescription() string {
return e.Name + "-" + e.Noddles.GetDescription()
}
func (e *Bacon) GetPrice() float32 {
return e.Price + e.Noddles.GetPrice()
}
main.go:
// 点一份面
// ramen := pkg.FriedRice{
ramen := pkg.Ramen{
Price: 10,
Name: "拉面",
}
// 加蛋
egg := pkg.Egg{
Noddles: ramen,
Price: 1,
Name: "鸡蛋",
}
// 加培根,在加了鸡蛋的基础上
bacon := pkg.Bacon{
Noddles: &egg,
Price: 2,
Name: "培根",
}
fmt.Println(bacon.GetDescription())
|
装饰者模式最重要的地方就是在装饰者角色处聚合了它实现的接口,即它既实现了抽象构件角色接口定义的方法又再次聚合了这个接口。又因为实现了相同的接口,可以让它可以多次嵌套。
装饰者模式可以带来比继承更加灵活的扩展功能,使用更加方便,可以通过组合不同的装饰者对象来获取具有不同行为状态的多样化的结果。装饰者模式比继承更具良好的扩展性,完美的遵循了开闭原则,动态的附加责任(可加可去,动态的)。
装饰类和被装饰类可以独立发展(新增装饰或被装饰类都不会影响到之前的,仅仅需要新增一个结构体且实现接口方法即可),不会相互耦合(装饰类动态的嵌套在被装饰者类上,不加也不会有任何问题,只是没有装饰罢了),装饰者模式是继承的一个替代模式,可以动态扩展一个实现类的功能
使用场景:
- 在不影响其他对象的情况下,以动态、透明的方式给单个对象添加职责。
- 当对象的功能要求可以动态的添加,也可以再动态撤销时(改为调用加功能之前的变量即可动态撤销,因为golang中结构体无法强转,无法通过将加功能的变量重新赋值为未加之前的状态,两者结构体不同)。
代理模式与装饰模式的区别:
- 代理模式是把当前的行为或功能委托给其他对象执行,代理类负责接口限定:是否可以调用真是角色,以及是否对发送到真是角色的消息进行变形处理,他不对被主题角色的功能做任何处理,保证原汁原味的调用,代理模式使用到机制开发就是AOP。
- 装饰模式是在要保证接口不变的情况下加强类的功能,他保证的是被修饰的对象功能比原始对象丰富。但不做准入条件和准入参数过滤
- 装饰者模式主要是增强目标对象,而代理是为了保护和隐藏目标对象(由代理来调用目标对象的方法)
- 装饰器模式关注于在一个对象上动态的添加方法,然而代理模式关注于控制对对象的访问。换句话说,用代理模式,代理类可以对它的客户隐藏一个对象的具体信息。因此,当使用代理模式的时候,我们常常在一个代理类中创建一个对象的实例(可以直接在内部进行传递,不暴露出去)。但当我们使用装饰器模式的时候,我们通常的做法是将原始对象作为一个参数或变量传给装饰者类。
桥接模式(有多个维度的对象,每个维度的组合都会有不同的结果。如window和linux播放多种格式的视频的实现代码肯定是不同的,就可以采用这种模式,可以提高扩展性,新增一个视频格式或系统只需要增加一个具体的对应角色即可)
将抽象与现实分离,使它们可以独立变化。它是用组合关系代替继承关系来实现,从而降低了抽象和实现这两个可变维度的耦合度。
桥接模式包含以下主要角色:
- 抽象化角色:定义抽象类,并包含一个对实现化对象的引用。
- 扩展抽象化角色:是抽象化角色的子类,实现父类中的业务方法,并通过组合关系调用实现化角色中的业务方法。
- 实现化角色:定义实现化角色的接口,供扩展抽象化角色调用。
- 具体实现化角色:给出实现化角色接口的具体实现。
在java中抽象化角色用abstract,实现化用interface,因此会说是将抽象与现实分离,但golang中没有抽象,所以本质上就是将两个关联的维度(也可以套更多维度,但是维度之间必须要有线性关系)进行解耦合,让他们两者可以进行独立变化。然后广度高的那个作为抽象化角色,其子类包含实现化角色的接口,通过传不同具体实现化角色来调用它的方法。不需要修改原系统,符合开闭原则,并且实现细节对客户透明。
开发一个可以在不同操作系统平台上播放多种格式的视频文件,不同操作系统是一个维度,不同播放格式是一个维度。一个操作系统可以播放不同格式的视频文件,操作系统的广度更大,因此操作系统作为抽象化角色,其子类包含对应的播放格式接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
// 实现化角色,播放格式接口
type VedioFile interface {
Decode(string) // 解码
}
// 具体实现化角色, 实现不同播放器的解码
type WMVFile struct{}
func (w WMVFile) Decode(dir string) {
fmt.Println("使用WMV格式播放了:" + dir)
}
type RMVBFile struct{}
func (r RMVBFile) Decode(dir string) {
fmt.Println("使用RMVB格式播放了:" + dir)
}
// 抽象化角色, 操作系统接口
type OperatingSystem interface {
Play(string) // 播放
}
type Windows struct {
VedioFile
}
func (w Windows) Play(dir string) {
fmt.Println("Windows 系统")
w.VedioFile.Decode(dir)
}
type Linux struct {
VedioFile
}
func (l Linux) Play(dir string) {
fmt.Println("Linux 系统")
l.VedioFile.Decode(dir)
}
main.go:
// 使用windows播放RMVB
var windows pkg.OperatingSystem = pkg.Windows{
VedioFile: pkg.RMVBFile{},
}
windows.Play("战狼")
|
它和装饰者看似很像,但是有很大的区别,装饰者模式只需要定义一个接口,但这个必须定义两个。并且装饰者模式扩展是可以不加的,但是这里如果不加实现化角色就会导致空指针。
外观模式(让底层提供一个统一的对外接口,客户调用此接口来访问底层,其实就是定义了一个方法让上层访问,底层所需要的部分数据和调用顺序已经在这个方法里面写好了,我们在日常工作中也经常使用)
又名门面模式,是一种通过为多个复杂的子系统提供一个一致的接口,而使这些子系统更加容易被访问的模式。该模式对外有一个统一接口,外部应用程序不用关系内部子系统的具体的细节,这样会大大降低应用程序的复杂度,提高了程序的可维护性。
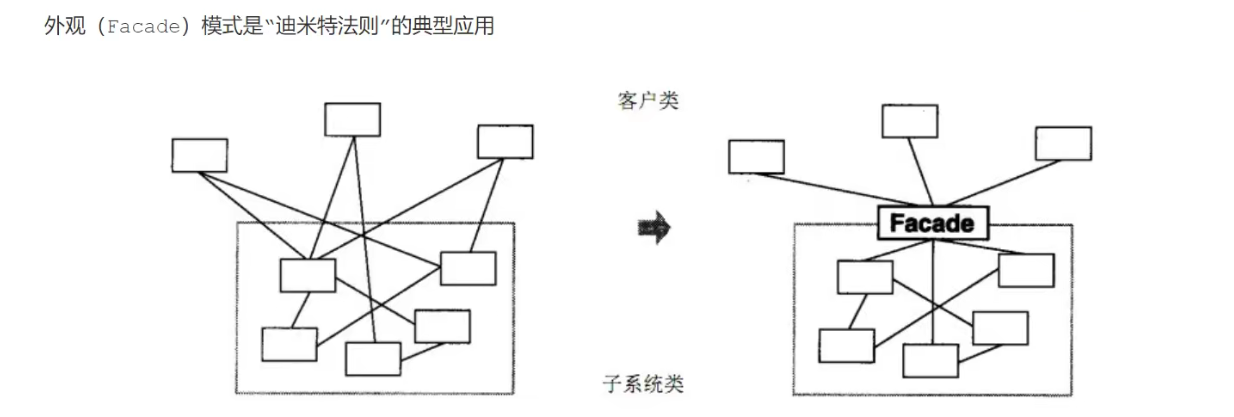
在日常编码工作中,我们都在有意无意的大量使用外观模式。只要是高层模块需要调度多个子系统(2个以上的类对象),我们都会自觉地创建一个新的类封装这些子系统,提供精简的接口,让高层模块可以更加容易地间接调用这些子系统的功能。尤其是现阶段各种第三方SDK、开源类库,很大概率都会使用外观模式。
外观模式包含以下主要角色:
- 外观角色:为多个子系统对外提供一个共同的接口。
- 子系统角色:实现系统的部分功能,客户可以通过外观角色访问它。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
type ProductSystem struct {
}
func (p *ProductSystem) GetProductInfo() {
fmt.Println("获取到商品信息")
}
type StockSystem struct {
}
func (s *StockSystem) GetStockInfo() {
fmt.Println("获取到库存信息")
}
type PromotionSystem struct {
}
func (p *PromotionSystem) GetPromotionInfo() {
fmt.Println("获取营销信息")
}
// 获取所有信息
func ProductDetail(product ProductSystem, stock StockSystem, promotion PromotionSystem) {
product.GetProductInfo()
stock.GetStockInfo()
promotion.GetPromotionInfo()
fmt.Println("整理完成商品详情页所有数据")
}
func main() {
product := pkg.ProductSystem{}
stock := pkg.StockSystem{}
promotion := pkg.PromotionSystem{}
pkg.ProductDetail(product, stock, promotion)
}
|
优缺点:
- 降低了子系统与客户端之间的耦合度,子系统的变化不会影响客户端。
- 对客户屏蔽了子系统的组件,减少了客户处理的对象数目,使得子系统使用起来更加容易。
- 不符合开闭原则,修改麻烦。
但是这样扩展很蠢,很少会有需要多个具体外观的情况,且这样增加了依然需要修改具体外观,还是不符合开闭原则
使用场景:
- 对分层结构系统构件时(高层调用底层),使用外观模式定义子系统中每层的入口点可以简化子系统之家的依赖关系。
- 当一个复杂系统的子系统很多时,外观模式可以为系统设计一个简单的接口供外界访问。
- 当客户端与多个子系统之间存在很大的联系时,引入外观模式可以将他们分离,从而提高子系统的独立性和可移植性。
组合模式(对于树型结构的解决方案,它让叶子节点和分支节点都实现同一个接口,通过调用根节点来递归的调用下面所有节点的方法,客户不需要关注细节,只需要调用一个方法就可以遍历所有的节点)
又名部分整体模式,是用于把一组相似的对象当作一个单一的对象。组合模式依据树型结构来组合对象,用来表示部分以及整体层次。这种类型属于结构型模式,它创建了对象组的树型结构。
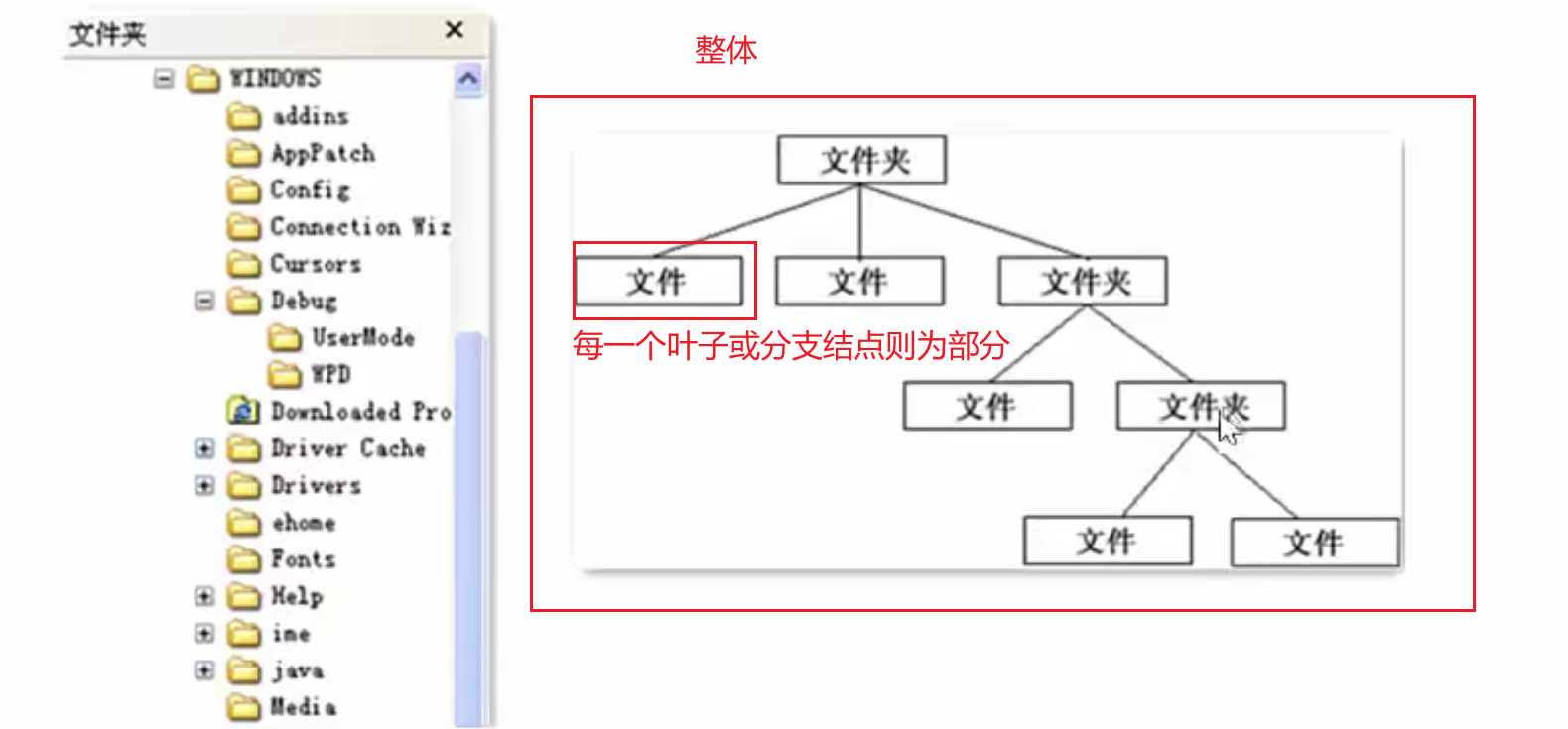
它有三个角色:
- 抽象根节点:定义系统各层次对象的共有方法和属性,可以预先定义一些默认行为和属性。
- 树枝节点:定义树枝节点的行为,存储子节点,组合树枝节点和叶子节点形成一个树形结构。
- 叶子节点:叶子节点对象,其下再无分支,是系统层次遍历的最小单位
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
|
// 抽象根节点,定义规范,在golang中根节点也属于部分,用struce来创建
type MenuComponent interface {
Add(MenuComponent)
GetName() string
Print()
}
// 树枝节点
type Menu struct {
Name string
Level int
MenuComponents []MenuComponent // 树枝节点下面还可能有叶子和树枝节点
}
// 树枝节点
func (m *Menu) Add(me MenuComponent) {
m.MenuComponents = append(m.MenuComponents, me)
}
func (m *Menu) GetName() string {
return m.Name
}
func (m *Menu) Print() {
// ---用于表现层次感
for i := 0; i < m.Level; i++ {
fmt.Print("---")
}
fmt.Println(m.Name)
for _, v := range m.MenuComponents {
// 递归
v.Print()
}
}
// 叶子节点
type MenuItem struct {
Name string
Level int
}
// 树枝节点
func (m *MenuItem) Add(me MenuComponent) {
}
func (m *MenuItem) GetName() string {
return m.Name
}
func (m *MenuItem) Print() {
for i := 0; i < m.Level; i++ {
fmt.Print("---")
}
fmt.Println(m.Name)
}
main.go:
// 创建根节点
menu := pkg.Menu{
Name: "系统管理",
Level: 1,
}
// 创建二级节点
menu1 := pkg.Menu{
Name: "菜单管理",
Level: 2,
}
{
menuItem1 := pkg.MenuItem{
Name: "页面访问",
Level: 3,
}
menuItem2 := pkg.MenuItem{
Name: "展开菜单",
Level: 3,
}
menu1.Add(&menuItem1)
menu1.Add(&menuItem2)
}
// 创建二级节点
menu2 := pkg.Menu{
Name: "权限配置",
Level: 2,
}
{
menuItem1 := pkg.MenuItem{
Name: "页面访问",
Level: 3,
}
menuItem2 := pkg.MenuItem{
Name: "提交保存",
Level: 3,
}
menu2.Add(&menuItem1)
menu2.Add(&menuItem2)
}
menu3 := pkg.Menu{
Name: "角色管理",
Level: 2,
}
{
menuItem1 := pkg.MenuItem{
Name: "页面访问",
Level: 3,
}
menuItem2 := pkg.MenuItem{
Name: "新增角色",
Level: 3,
}
menu3.Add(&menuItem1)
menu3.Add(&menuItem2)
}
menu.Add(&menu1)
menu.Add(&menu2)
menu.Add(&menu3)
menu.Print()
|

优点:
- 组合模式可以清楚的定义分层次的复杂对象,表示对象的全部或部分层次,它让客户端忽略了层次的差异,方便对整个层次结构进行控制。
- 客户端可以一致地使用一个组合结构或其中的单个对象(因为两者都实现了同一个接口,调用都一样),不必关心处理的是单个对象还是整个组合结构,简化了客户端代码。
- 在组合模式中增加新的树枝节点和叶子节点都很方便,无须对现有类库进行任何修改,符合开闭原则。(但是对叶子节点加子节点就需要将叶子节点改为分支节点)
- 组合模式为 树形结构的面向对象实现 提供了一种灵活的解决方案,通过叶子节点和分支节点的递归组合,可以形成复杂的树形结构,但对树形结构的控制却非常简单(实现同一个接口,调用接口方法即可控制)。
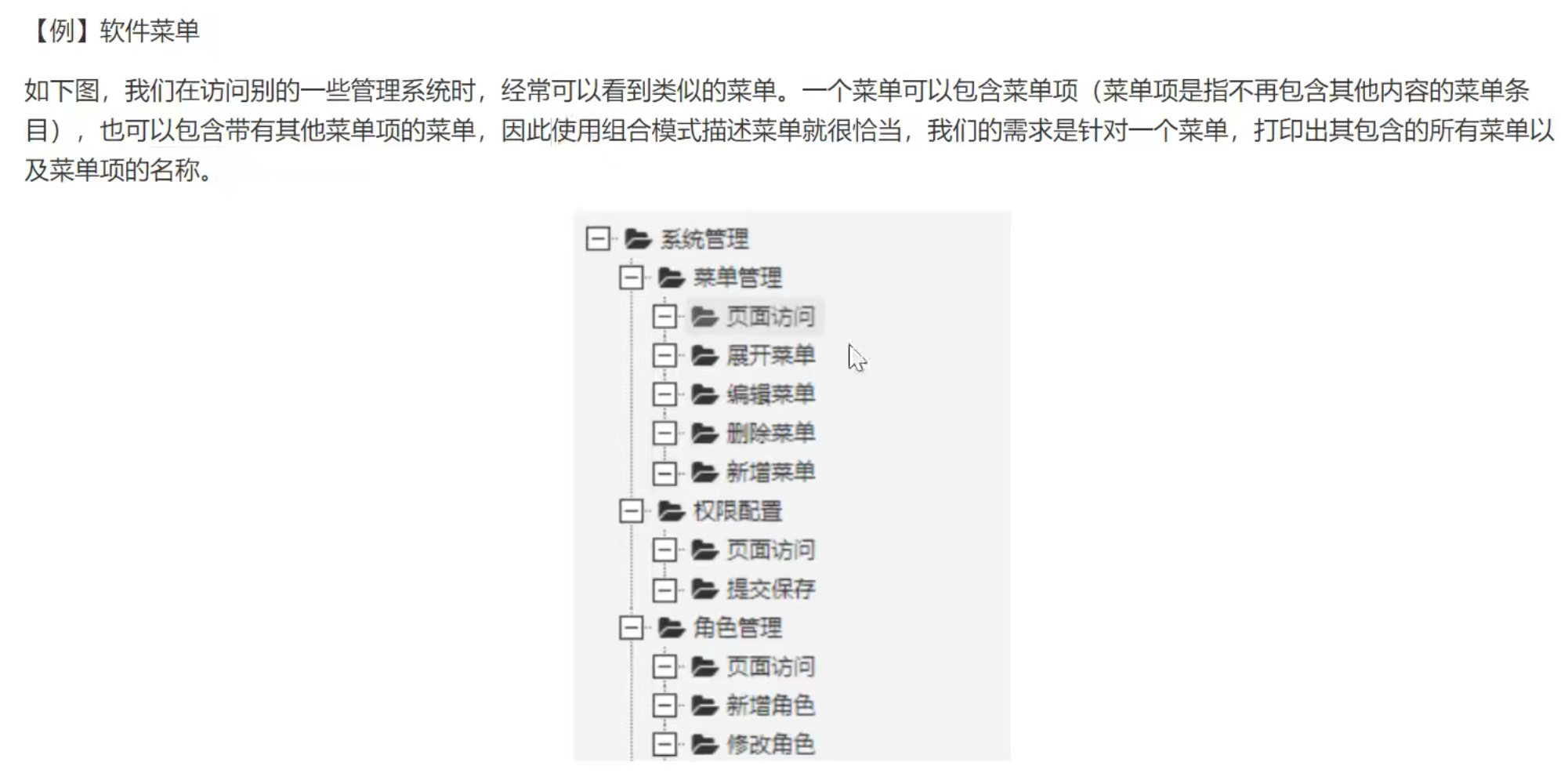
组合模式正是应树形结构而生,只要出现树形结构的地方就可以使用组合模式来实现。比如文件目录显示、菜单栏等树形结构数据的操作。
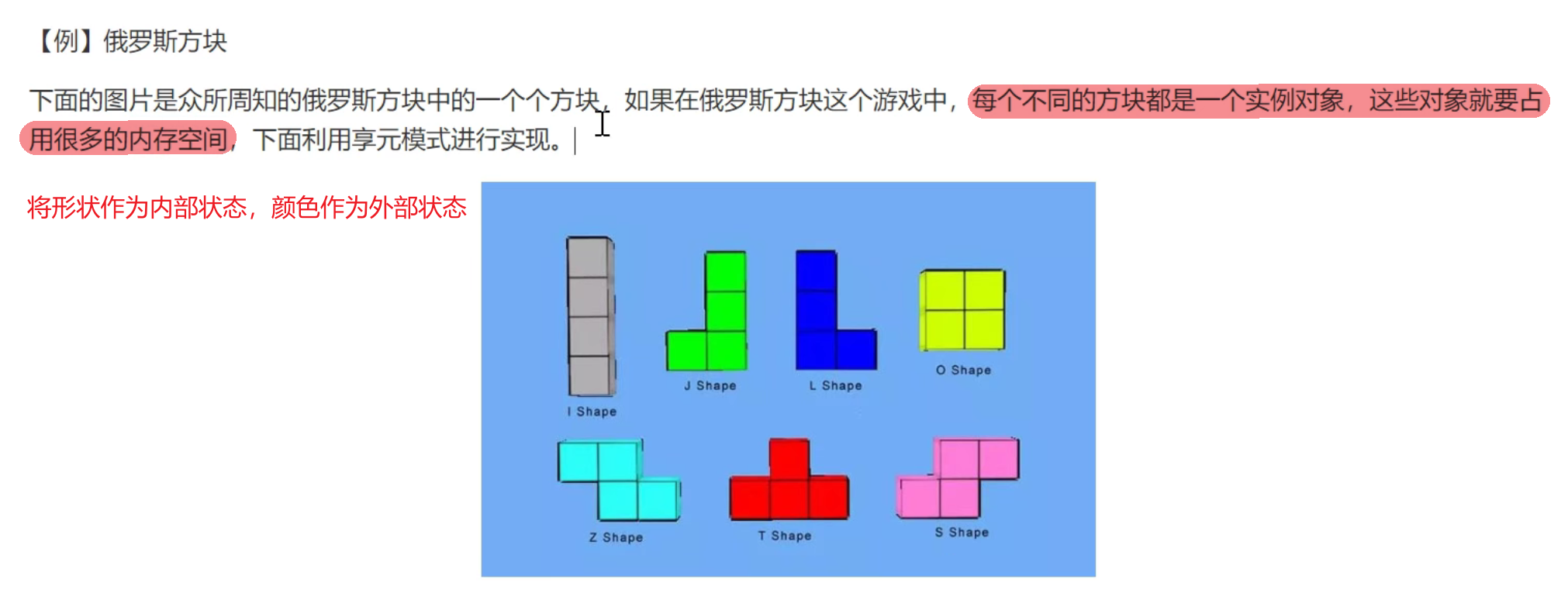
享元模式(享元模式和单例模式类似,但享元模式即可以再次创建对象,也可以取缓存对象,单例就只有一个,它的使用场景是一个结构体有大量相同相似的对象,其中有部分元素不同,其他都相同,则可以通过此模式减少内存损耗,通过外部状态来改变某一个对象的属性)
运用共享技术来有效的支持大量细粒度对象的复用。它通过共享已经存在的对象来大幅度减少需要创建的对象数量,避免大量相似对象的开销,从而提高系统资源的利用率。
享元模式主要用于减少创建对象的数量,以减少内存占用和提高性能。在有大量对象时,有可能会造成内存溢出,我们把其中共同的部分抽离出来,如果有相同的业务请求,直接返回在内存中已有的对象,避免重新创建。
它和单例有点相似,但是单例并没有内外部之分,并且单例通常只有Get方法,因此如果用单例来实现俄罗斯方块就需要每个形状每个颜色都写一个单例,依然浪费了过多的内存。
这个模式最关键在于用map来存储这些对象,用单例模式和工厂模式获取工厂然后获取这些对象,而它的状态大部分可以通过外部化实现。
享元模式中存在以下两种状态:
- 内部状态:即不会随着环境的改变而改变的可共享部分(系统中仅存在单份,如示例中的形状)。
- 外部状态:指随着环境改变而改变的不可共享的部分。享元模式的实现要领就是区分应用中的这两种状态,并将外部状态外部化(如示例中的颜色,随着游戏进行改变颜色,主要通过方法参数进行传递,又或者连接池的用户名密码ip等在一开始new的时候就已经确定好了,不再进行更改,这部分就是内部状态,而回收时通过参数将这个连接改为可用,这就为外部状态)。
因此在设计时可以将这个结构体不发生改变的部分设为内部状态,时常改变的部分设为外部状态(即一个系统中生成了大量同一类结构体,只是内容不同)。
享元模式主要有以下角色:
- 抽象享元角色:通常是一个接口或抽象类,在抽象享元类中声明了具体的享元类公共的方法,这些方法可以向外界提供享元对象的内部数据(内部状态),同时也可以通过这些方法来设置外部数据(外部状态)。
- 具体享元角色:它实现了抽象享元类,称为享元对象。在具体享元类中为内部状态提供了存储空间。通常我们可以结合单例模式来设计具体享元类,为每一个具体享元类提供唯一的享元对象。(内部状态)
- 非享元角色:并不是所有的抽象享元类的子类都需要被共享,不能被共享的子类可设计为非共享具体享元类,当需要一个非共享具体享元类的对象时可以直接通过实例化创建。(外部状态)
- 享元工厂角色:负责创建和管理享元角色。当客户对象请求一个享元对象时,享元工厂检查系统中是否存在符合要求的享元对象,如果存在则提供给客户;如果不存在的话,则创建一个新的享元对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
var factory *BoxFactory
var once sync.Once
// 抽象享元角色
type Box interface {
// 获取图形
GetShape() string
// 显示图形和形状,颜色作为外部状态以参数的形式进行传递
DisPlay(color string)
}
// 具体享元角色
type IBox struct {
Color string
}
func (i *IBox) GetShape() string {
return "IBox" + i.Color
}
func (i *IBox) DisPlay(color string) {
i.Color = color
}
type OBox struct {
Color string
}
func (i *OBox) GetShape() string {
return "OBox" + i.Color
}
func (i *OBox) DisPlay(color string) {
i.Color = color
}
// 享元工厂角色,通过单例来设计工厂类
type BoxFactory struct {
Box map[string]Box
}
func (bf *BoxFactory) GetBox(boxName string) Box {
return bf.Box[boxName]
}
func GetBoxFactory() *BoxFactory {
// 第一次调用时初始化存储map
once.Do(func() {
factory = &BoxFactory{
Box: map[string]Box{},
}
factory.Box["I"] = &IBox{}
factory.Box["O"] = &OBox{}
})
return factory
}
main.go:
// 创建工厂
factory := pkg.GetBoxFactory()
// map中存储的是指针,因此此时修改box1会影响到box
box := factory.GetBox("O")
box1 := factory.GetBox("O")
// 为false是因为&box取的是获取的指针的指针,获取的指针存到了两个不同的变量中,其指针肯定也不同
fmt.Println(&box == &box1)
box1.DisPlay("绿色")
fmt.Println(box)
|
优缺点:
- 极大减少内存中相似或相同的数量,节约系统资源,提高系统性能。
- 享元模式中的外部状态相对独立,且不影响内部状态(如俄罗斯方块中更改颜色不会影响到形状)。
- 缺点是为了使对象可以共享,需要将享元对象的部分状态外部化,分离内部状态和外部状态,使程序逻辑复杂。
使用场景:
- 一个系统中有大量相同或者相似的对象,造成内存的大量耗费(同一个结构体,成员变量不同)。
- 对象的大部分状态都可以外部化,可以将这些外部状态传入对象中。
- 在使用享元模式时需要维护一个存储享元对象的享元池,而这需要耗费一定的系统资源,因此,应当在需要多次重复使用同一类对象时才值得使用享元模式。(如果这个对象在系统中使用的次数少,采用享元模式反而会得不偿失)
享元模式和单例模式的区别:
- 享元模式可以再次创建对象,也可以取缓存对象。单例模式则是严格控制单个进程中只有一个实例对象
- 享元模式可以通过自己实现对外部的单例,也可以在需要的使用创建更多的对象。单例模式是自身控制,需要增加不属于该对象本身的逻辑
- 两者都可以实现节省对象创建的时间
行为型模式(11种)
行为性模式用于描述程序在运行时复杂的流程控制,即描述多个类或对象之间怎样相互协作共同完成单个对象都无法单独完成的任务,它涉及算法与对象间职责的分配。
行为型模式分为类行为模式和对象行为模式,前者采用继承机制来在类间分派行为,后者采用组合或聚合在对象间分配行为。由于组合关系或聚合关系比继承关系耦合度低,满足“合成复用原则”,所以对象行为模式比类行为模式具有更大的灵活性。
模板方法模式(当一个系统是按已知的某种流程运行的,只有其中部分方法逻辑不同,则可以使用此模式,使其模板化,而不同的部分则通过子类的匿名内部类来重写其方法,简少重复代码)
在面向对象程序设计过程中,程序员常常会遇到某种情况:设计一个系统时知道了算法所需的关键步骤,而且确定了这些步骤的执行顺序,但某些步骤的具体实现还未知,或者说某些步骤的实现与具体的环境相关。
模板方法模式就是定义一个操作中的算法骨架,而将算法的一些步骤延迟到子类中,使得子类可以在不改变该算法结构的情况下重新定义该算法的某些特定步骤。
模板方法模式包含以下主要角色:
- 抽象类:负责给出一个算法的轮廓和骨架。它由一个模板方法和若干个基本方法构成。
- 模板方法:定义了算法的骨架,按某种顺序调用其包含的基本方法(设置 执行顺序 的方法)。
- 基本方法:是 实现算法各个步骤的方法(单一步骤的详细实现方法),是模板方法的组成部分。基本方法又可以分为三种:
- 抽象方法:一个抽象方法由抽象类声明,并要求由其具体子类必须实现。
- 具体方法:一个具体方法由一个抽象类或具体类 声明并实现,其子类可以进行覆盖也可以直接继承(在父类中就已经实现了此方法)。
- 钩子方法:在抽象类中已经实现,包括用于判断的逻辑方法和需要子类重写空方法两种。(一般钩子方法是用于判断的逻辑方法,这类方法名一般为IsXxx,返回值类型为bool类型,在父类中实现然后子类继承重写【如父类直接返回false,在子类中再根据情况返回布尔值】)
- 具体子类:实现抽象类中所定义的抽象方法和钩子方法,它们是一个顶级逻辑的组成步骤。
模板模式是OOP编程中的一把神兵利器,用好了能够提高代码的复用程度,大大提高开发效率。例如,我们可以在父类中定义完成一个任务的几个步骤并分别给出一个默认实现,然后子类继承父类,子类只需要重写自己感兴趣的方法即可,剩余逻辑都可以复用父类的代码。Spring源码中就大量充斥着这样的套路。但是在go语言中,连类都没有,更别提继承了,那如何才能使出这种套路呢?答案就是内嵌匿名结构体。
如果一个struct A中内嵌了另一个匿名的struct B, 那么A就可以【直接】访问B中所有的字段和方法。这就是Go语言间接实现继承的唯一方法,内嵌匿名结构体。如果在定义A时给B进行了命名,比如b, 那调用时就只能 a.b.bField(), a.b.bMethod()了,完全失去了继承的意义。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
// 抽象类,定义流程
type Cooker interface {
pourOil() // 倒油
heatOil() // 热油
pourVegetable() // 倒蔬菜
pourSauce() // 倒调料
fry() // 翻炒
// 可以加钩子函数然后有基本方法结构体实现
}
// 模板方法,不写成方法是避免被子类重写
func doCook(cook Cooker) {
cook.pourOil()
cook.heatOil()
cook.pourVegetable()
cook.pourSauce()
cook.fry()
}
// 基本方法的结构体
type Cookie struct{}
// 具体方法
func (c Cookie) pourOil() {
fmt.Println("倒油")
}
func (c Cookie) heatOil() {
fmt.Println("热油")
}
// 抽象方法,交由下一层重写
func (c Cookie) pourVegetable() {
}
func (c Cookie) pourSauce() {
}
func (c Cookie) fry() {
fmt.Println("翻炒")
}
// 具体子类
type BaoCai struct {
// 由于golang中没有继承,只能通过这种方式实现模板方法
// 要注意的是这里的Cookie不能起名,起了后就无法再重写Cookie的方法了,只有内嵌匿名结构体才能实现重写,不匿名调用时都需要加上成员变量的名称才行
Cookie
}
// 重写抽象方法
func (b *BaoCai) pourVegetable() {
fmt.Println("放包菜")
}
func (b *BaoCai) pourSauce() {
fmt.Println("放辣椒")
}
func main() {
baocai := &BaoCai{}
doCook(baocai)
}
|
但是这样只能是勉强实现了模板模式,并不优雅,问题很多。编译器无法强制"子类"来实现"父类"定义的步骤方法, 编写"子类"有可能会忘记实现,但这一错误要到运行时才能被发现(因为只有结构体实现接口没实现完才会报错,对父类的方法重写不会涉及报错情况)。或者忘记使用doCook也会在运行时才能被发现。这两个问题目前在golang中是完全无解的。
Go语言的设计哲学是简单和简洁,即使用最少的关键字、最少的语法来实现最常用的功能。也就造成了牺牲抽象能力,牺牲继承等。
策略模式(达到一个目的有多种办法,如登录时可以微信可以QQ等,此时就可以使用此方法,把微信和QQ的具体细节分别存入不同的函数中,函数存入map,客户端通过map-key来调用对应的方法,可以省略过多的if-else语句,美化代码)
作为一个编程人员,开发肯定需要选择一款开发工具,而可以选择代码开发的工具很多,可以用vscode,也可以用goland,甚至是其他工具。
该模式定义了一系列算法,并将每个算法封装起来,使它们可以相互替换(就如开发工具),算法的变化不会影响到使用算法的客户(最终结果)。策略模式属于对象行为模式,它通过对算法进行封装,把使用算法的责任和算法的实现分割开来,并委派给不同的对象对这些算法进行管理。
我们在用GO编程的时候经常碰到多层控制语句(if-else if…),一层又一层,既不优雅,也不利于后续维护。
虽然按这种模式写起来简单快捷,但它也违背了面向对象的两个原则:
- 单一职责原则:多个控制语句,意味着拥有多种功能;
- 开闭原则:当要进行修改时,原有代码不可避免要被修改;
此时就可以采用策略模式来替换这类多层控制语句。又或者,我们在为一个对象添加行为时发现,该对象可以用多种方式去达成同一个目的,区别在于使用场景不同、效率不同。
主要角色如下:
- 抽象策略类:这是一个抽象角色,通常由一个接口或抽象类实现。此角色给出所有的具体策略类所需的接口。
- 具体策略类:实现了抽象策略定义的接口,提供具体的算法实现或行为。
- 环境类:持有一个策略类的引用,最终给客户端调用。
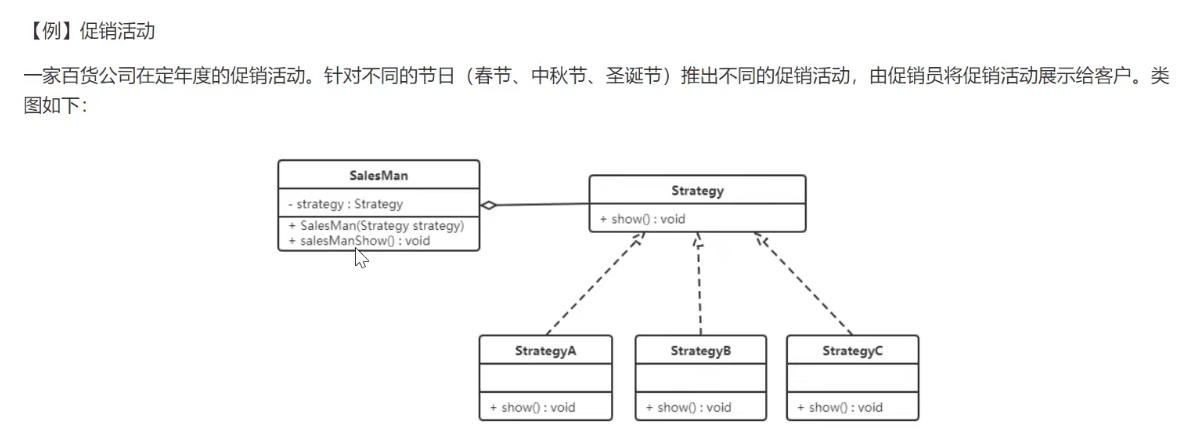
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
// 抽象策略类,实现此接口,则为一个策略
type Strategy interface {
show()
}
// 具体策略类,提供不同的策略,每个节日的具体促销活动
type StrategyA struct{}
func (s *StrategyA) show() {
fmt.Println("买一送一")
}
type StrategyB struct{}
func (s *StrategyB) show() {
fmt.Println("满200减50")
}
type StrategyC struct{}
func (s *StrategyC) show() {
fmt.Println("满1000元加一元换购任意200元以下商品")
}
// 环境类,具体策略的执行者,这里可以理解为销售员
type SalesMan struct {
strategy Strategy
}
func (s *SalesMan) SalesManShow() {
s.strategy.show()
}
func (s *SalesMan) SetSlesMan(strategy Strategy) {
s.strategy = strategy
}
func main() {
salesMan := SalesMan{}
strategyFunc := make(map[string]func(v ...interface{}))
strategyFunc["A"] = func(v ...interface{}) {
salesMan.SetSlesMan(&StrategyA{})
}
strategyFunc["B"] = func(v ...interface{}) {
salesMan.SetSlesMan(&StrategyB{})
}
strategyFunc["C"] = func(v ...interface{}) {
salesMan.SetSlesMan(&StrategyC{})
}
strategyFunc["A"]()
salesMan.SalesManShow()
}
|
但是策略的选择还是需要人为了解策略实现后进行选择,甚至还是不可避免地需要使用多个if else的嵌套来选择策略。因此可以预先将策略类保存在一个map中,具体的开发时候,通过一个key来获取这个策略的实例。这样的话,策略的选择就通过变成了一个key的选择,甚至可以做到通过文档规范来制约。
再重申一遍策略模式的精髓是封装一组算法实现以供使用时的调度,golang里面有一个很重要的语法糖就是func() ——方法变量,也因为,golang实现类似策略模式的做法,不需要依赖于对象而进行。
这样无论是算法的封装还是调度都从业务场景中解耦了。当然,缺点就是如果需要扩展策略,就要到增加一个Entry<K,V>,没有传统的实现方式中直接扩展一个实现了策略接口的对象那么方便(但是传统实现方式依然无法摆脱if-elseif的问题),这两个还得看具体的项目取舍。
优点:
- 策略类之间可以自由切换。由于策略类都实现同一个接口,所有它们之间可以自由切换。
- 易于扩展。增加一个新的策略只需要添加一个具体的策略类即可,基本不需要改变原有的代码,符合开闭原则
- 避免使用多重条件选择语句,充分体现面向对象设计思想
缺点:
- 客户端必须知道所有的策略类,才能自行决定使用哪一个策略类。即所有策略类都需要对外暴露。
- 策略模式将造成产生很多的策略类,可以通过使用享元模式在一定程度上减少对象的数量。
使用场景:
- 一个系统需要动态地在几种算法中选择一种时,可以将每个算法封装到策略类中
- 一个类定义了多种行为,并且这些行为在这个类的操作中以多个条件语句的形式出现,可将每个条件分支移入它们各自的策略类中以代替这些条件语句。
- 系统中各算法彼此完全独立,且要求对客户隐藏具体算法的实现细节时。
- 系统要求使用算法的客户不应该知道其操作的数据时,可使用策略模式来隐藏与算法相关的数据结构。
- 多个类只区别在表现行为不同,可以使用策略模式,在运行时动态选择具体要执行的行为。
命令模式(在请求方和执行方中插入命令层,请求方调用命令层,请求方不再关注是哪个执行方,由命令层分配执行方执行,命令层对请求方的数据加工或转存再调用执行方。新增命令调用其他的执行方时,请求方就可以同步使用新的命令,不需要了解执行方的具体代码,屏蔽了底层的复杂实现。可以实现队列的需求,延时调用和顺序调用的功能,还可以实现回滚功能。多个请求者去调用一个命令层,一个命令层再去调用多个执行者)
将一个请求封装为一个对象,使发出请求的责任和执行请求的责任分隔开。这样两者之间通过命令对象进行沟通,这样方便将命令对象进行存储、传递、调用、增加和管理。
主要包含以下角色:
- 抽象命令类角色:定义命令的接口,声明执行的方法。
- 具体命令类角色:具体的命令,实现命令接口。通常会持有接收者,并调用接收者的功能来完成命令要执行的操作。
- 实现者/接收者角色:真正执行命令的对象。任何类都可能成为一个接收者,只要它能够实现命令要求实现的相应功能。
- 调用者/请求者角色:要求命令对象执行请求,通常会持有命令对象,可以持有很多的命令对象。这个是客户端真正触发命令并要求命令执行相应操作的地方,也就是说相当于使用命令对象的入口。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
|
// 订单
type Order struct {
table int // 桌号
foodDir map[string]int // 食物,key为食物名称,value为份数
}
func (o *Order) setFood(name string, num int) {
if o.foodDir == nil {
o.foodDir = make(map[string]int)
}
o.foodDir[name] = num
}
// 厨师类,实现者/接收者角色
type SeniorCher struct {
Name string
}
// 制作食物
func (s SeniorCher) makeFood(num int, foodName string) {
fmt.Println("厨师 " + s.Name + "制作了" + strconv.Itoa(num) + "份" + foodName)
}
// 服务员类,调用者/请求者角色
type Waitor struct {
Name string
Commands []Command
}
// 它可以持有多个命令对象,让不同类型的命令都走一个通道(只要实现了抽象命令类即可)
func (w *Waitor) setCommand(cmd Command) {
w.Commands = append(w.Commands, cmd)
}
// 发起命令
func (w *Waitor) orderUp() {
fmt.Println(w.Name + "服务员接单")
for _, v := range w.Commands {
if v != nil {
v.execute()
}
}
}
// 抽象命令类角色
type Command interface {
execute()
}
// 具体命令类角色
type OrderCommand struct {
Order
SeniorCher
}
func (o *OrderCommand) execute() {
fmt.Println("开始制作" + strconv.Itoa(o.Order.table) + "桌的订单")
for i, v := range o.foodDir {
o.SeniorCher.makeFood(v, i)
}
fmt.Println(strconv.Itoa(o.Order.table) + "桌的订单准备完毕")
}
func main() {
// 一号桌点单
order1 := Order{
table: 1,
}
order1.setFood("西红柿炒蛋", 1)
order1.setFood("可乐", 2)
// 二号桌点单
order2 := Order{
table: 2,
}
order2.setFood("青椒肉丝", 1)
order2.setFood("雪碧", 1)
// 创建命令对象
OrderCommand1 := OrderCommand{
Order: order1,
SeniorCher: SeniorCher{"李大厨"},
}
OrderCommand2 := OrderCommand{
Order: order2,
SeniorCher: SeniorCher{"王助手"},
}
// 服务员发起订单请求
waitor := Waitor{
Name: "小美",
}
waitor.setCommand(&OrderCommand1)
waitor.setCommand(&OrderCommand2)
// 发起命令
waitor.orderUp()
}
|
优点:
- 通过引入中间件(抽象接口),降低系统的耦合度。命令模式能将调用操作的对象与实现该操作的对象解耦(增加了一个中间件)。
- 支持命令队列,顺序执行。也可以在现有命令的基础上增加额外功能,如日志记录,结合装饰者模式会更加灵活。
- 增加或删除命令非常方便。采用命令模式增加与删除命令不会影响其他类,只需要新增一个具体命令类角色即可(即使与厨师功能不相关都可,这样子服务员除了给厨师发送做饭的命令还可以给其他类发送命令)。它满足开闭原则,对扩展比较灵活。
- 可以实现宏命令。命令模式和组合模式结合,将多个命令装配成一个组合命令,即为宏命令(将命令包装成一棵树,层层向下进行执行)
- 方便实现Undo和Redo操作(撤销与恢复)。命令模式可以与备忘录模式结合,实现命令的撤销与恢复。
缺点:
- 使用命令模式可能会导致某些系统有过多的具体命令类。
- 系统结构更加复杂。
使用场景:
- 系统需要将请求调用者和请求接收者解耦,使得调用者和接收者不直接交互。
- 现实语义中具备“命令”的操作(如命令菜单、Shell命令等)。
- 系统需要在不同的时间指定请求、将请求排队(谁先下单谁先做,因为是存在切片中,是有序的)和执行请求。
- 系统需要支持命令的撤销和恢复操作。
- 需要支持命令宏(即命令组合操作)。
命令模式(Command Pattern)是对命令的封装。每一个命令都是一个操作,请求方发出请求要求执行一个操作;接收方收到请求,并执行操作。
责任链模式(通常作用于过滤器,过滤敏感词。一个对象经由多个对象处理,这个对象处理不了则交给下一级)
在现实生活中,常常会出现这样的事例:一个请求有多个对象可以处理,但每个对象的处理条件或权限不同。例如公司员工请假,可批假的领导有部门负责人、副总经理、总经理等,但每个领导能批准的天数不同,员工必须根据自己要请假的天数去找不同的领导签名,也就是说员工必须记住每个领导的姓名、电话和地址等信息,这无疑是增加了难度。
责任链模式又名职责链模式,为了避免请求发送者与多个请求处理者耦合在一起,将所有请求的处理者通过前一对象记住下一个对象的引用而连成一条链;当有请求发生时,可将请求沿着这条链传递,直到有对象处理它为止。
主要包含以下角色:
- 抽象处理者角色:定义一个处理请求的接口,包含抽象处理方法和一个后继连接。
- 具体处理者角色:实现抽象处理者的处理方法,判断能否处理本次请求,如果可以处理请求则处理,否则将该请求转给它的后继者。
- 客户类角色:创建处理链,并向链头的具体处理者对象提交请求,它不关心处理细节和请求的传递过程(即客户端)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
// 请假条
type Leave struct {
name string
num int
}
// 抽象处理者角色
type Handler interface {
submit(l Leave)
}
// 部门领导,具体处理者角色
type GroupLeader struct {
nextHandler Handler // 上级领导
}
func (g *GroupLeader) submit(le Leave) {
fmt.Println("小组长审批同意")
// 小组长无法处理三天以上的则向后延,但是需要小组长先同意再继续
if g.nextHandler != nil && le.num > 1 {
g.nextHandler.submit(le)
} else {
fmt.Println("流程结束")
}
}
// 副经理
type Manager struct {
nextHandler Handler // 上级领导
}
func (m *Manager) submit(le Leave) {
fmt.Println("副经理审批同意")
// 小组长无法处理三天以上的则向后延,但是需要小组长先同意再继续
if m.nextHandler != nil && le.num > 3 {
m.nextHandler.submit(le)
} else {
fmt.Println("流程结束")
}
}
// 总经理
type GeneralManager struct {
nextHandler Handler // 上级领导
}
func (g *GeneralManager) submit(le Leave) {
fmt.Println("总经理审批同意")
// 小组长无法处理三天以上的则向后延,但是需要小组长先同意再继续
if g.nextHandler != nil && le.num > 7 {
g.nextHandler.submit(le)
} else {
fmt.Println("流程结束")
}
}
func main() {
// 创建请假条
leave := Leave{
name: "张三",
num: 3,
}
// 创建领导链
groupLeader := GroupLeader{}
manager := Manager{}
generalManager := GeneralManager{}
groupLeader.nextHandler = &manager
manager.nextHandler = &generalManager
groupLeader.submit(leave)
}
|
优点
- 降低了请求发送者和接收者之间的耦合度
- 增强了系统的可扩展性。可以根据需要增加新的具体处理类,满足开闭原则。
- 增强了给对象指派职责的灵活性。当工作流程发生变化,可以动态的改变链内的成员或修改它们的次序,也可动态的新增或删除职责。
- 责任链简化了对象之间的连接,一个对象只需要保持一个指向其后继者的引用,不需要保持其他所有处理者的引用,这避免了客户端使用众多的if-elseif语句。
- 每个类只需要处理自己该处理的工作,不能处理的传递给下一处对象完成,明确各类的责任范围,符合类的单一职责原则。
缺点:
- 不能保证每一个请求都被处理。由于请求没有明确的接收者,所以不能保证它一定会被处理,该请求可能一直传到链的末端都得不到处理(如上例中请假天数过大就没处理,实际开发中要仔细考虑)
- 对较长的职责链,请求的处理可能涉及多个处理对象(一直向下传递),系统性能将受到一定的影响(所以链不能太长,要适当)。
- 职责链建立的合理性要靠客户端来保证,增加了客户端的复杂性,可能会由于职责链的错误设置而导致系统出错,如可能会造成循环调用(最终又指向最初)
使用场景:
- 消息过滤器,权限拦截器
- 用户发帖内容进行广告过滤,涉黄过滤,敏感词过滤等
除了采用显性链式的情况外,也可以将具体处理者存为一个切片,切片本质是一个数组(和链表类似,属于有序的集合),从头到尾,只是增加了一个基础处理者,这样子在客户端就能一目了然的看明白链的顺序。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
// 假设我们现在有个校园论坛,由于社区规章制度、广告、法律法规的原因需要对用户的发言进行敏感词过滤
// 如果被判定为敏感词,那么这篇帖子将会被封禁
// SensitiveWordFilter 敏感词过滤器,判定是否是敏感词
type SensitiveWordFilter interface {
Filter(content string) bool
}
// SensitiveWordFilterChain 职责链
type SensitiveWordFilterChain struct {
filters []SensitiveWordFilter
}
// AddFilter 添加一个过滤器
func (c *SensitiveWordFilterChain) AddFilter(filter SensitiveWordFilter) {
c.filters = append(c.filters, filter)
}
// Filter 执行过滤
func (c *SensitiveWordFilterChain) Filter(content string) bool {
for _, filter := range c.filters {
// 如果发现敏感直接返回结果
if filter.Filter(content) {
return true
}
}
return false
}
// AdSensitiveWordFilter 广告
type AdSensitiveWordFilter struct{}
// Filter 实现过滤算法
func (f *AdSensitiveWordFilter) Filter(content string) bool {
if strings.Contains(content, "广告") {
fmt.Println("广告敏感")
return false
}
return true
}
// PoliticalWordFilter 政治敏感
type PoliticalWordFilter struct{}
// Filter 实现过滤算法
func (f *PoliticalWordFilter) Filter(content string) bool {
if strings.Contains(content, "政治") {
fmt.Println("政治敏感")
return false
}
return true
}
func main() {
// 创建责任链
chain := &SensitiveWordFilterChain{}
chain.AddFilter(&AdSensitiveWordFilter{})
chain.AddFilter(&PoliticalWordFilter{})
chain.Filter("广告敏感")
}
|
状态模式(当对象根据某状态字段进行不同行为时,如QQ在线离线情况。将结构体中的状态字段包装成一个对象,减少庞大的ifelse语句块)
状态模式与有限状态机的概念紧密相关。其主要思想是程序在任意时刻仅可处于几种有限的状态中。 在任何一个特定状态中, 程序的行为都不相同, 且可瞬间从一个状态切换到另一个状态。 不过, 根据当前状态, 程序可能会切换到另外一种状态, 也可能会保持当前状态不变。 这些数量有限且预先定义的状态切换规则被称为转移 。
状态机通常由众多条件运算符 ( if或 switch ) 实现, 可根据对象的当前状态选择相应的行为。基于条件语句的状态机会暴露其最大的弱点:为了能根据当前状态选择完成相应行为的方法, 绝大部分方法中会包含复杂的条件语句。修改其转换逻辑可能会涉及到修改所有方法中的状态条件语句,导致代码的维护工作非常艰难。
这个问题会随着项目进行变得越发严重。 我们很难在设计阶段预测到所有可能的状态和转换。 随着时间推移, 最初仅包含有限条件语句的简洁状态机可能会变成臃肿的一团乱麻。
而状态模式则是解决这一问题。它对有状态的对象,把复杂的判断逻辑提取到不同的状态对象中,允许状态对象在其内部状态发生变化时改变其行为。
状态模式建议为对象的所有可能状态新建一个类, 然后将所有状态的对应行为抽取到这些类中。
原始对象被称为上下文 (context), 它并不会自行实现所有行为, 而是会保存一个指向表示当前状态的状态对象的引用, 且将所有与状态相关的工作委派给该对象。
这个结构可能看上去与策略模式相似, 但有一个关键性的不同——在状态模式中, 特定状态知道其他所有状态的存在, 且能触发从一个状态到另一个状态的转换; 策略则几乎完全不知道其他策略的存在。
主要包含以下角色:
- 环境角色:也称上下文,它定义了客户程序需要的接口,维护一个当前状态,并将与状态相关的操作委托给当前状态对象来处理。
- 抽象状态角色:定义一个接口,用以封装环境对象中的特定状态所对应的行为。
- 具体状态角色:实现抽象状态所对应的行为。通过消除臃肿的状态机条件语句简化上下文代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
// 定义状态
var (
stop = stopState{}
run = runState{}
)
// 抽象状态角色
type LiftState interface {
stop(con *liftContext)
run(con *liftContext)
}
// 具体状态角色
type runState struct{}
func (r runState) stop(con *liftContext) {
fmt.Println("关闭电梯")
con.liftState = stop
}
// 运行时无法再运行
func (r runState) run(con *liftContext) {
fmt.Println("已经在运行状态了")
}
type stopState struct{}
func (s stopState) stop(con *liftContext) {
fmt.Println("停止状态不可以再停止")
}
// 运行时无法再运行
func (s stopState) run(con *liftContext) {
fmt.Println("停止状态可以运行电梯")
con.liftState = run
}
// 环境角色,也就是原对象,里面的status则是原本的状态,是一个基础数据类型,将其换成接口
type liftContext struct {
Name string //电梯
liftState LiftState
}
func main() {
liftContext := liftContext{
Name: "XX电梯",
liftState: stopState{}, //设置为停止状态
}
// 调用了关闭状态的run方法,此时电梯状态变为了运行
liftContext.liftState.run(&liftContext)
// 调用了启动状态的stop方法,此时电梯状态变为了停止
liftContext.liftState.stop(&liftContext)
// 后续如果新增了方法,如断电方法,抽象、具体都得修改代码,也得新增一个断电功能
}
|
优点:
- 将所有与某个状态有关的行为放到一个类中,并且可以方便的增加新的状态,只需要改变对象的状态即可改变对象的行为。
- 允许状态转换逻辑与状态对象合成一体,而不是一个巨大的条件语句块。
缺点:
- 状态模式的使用必然会增加系统类和对象的个数。
- 状态模式的结构与实现都较为复杂,如果使用不当将导致程序结构和代码的混乱。
- 状态模式对开闭原则的支持不太友好,新增状态有可能会修改之前状态中的代码。对于可以切换状态的状态模式,增加新的状态类需要修改那些负责状态转换的源代码,否则无法切换到新增状态,而且修改某个状态类的行为也需修改对应类的源代码。
- 如果状态机只有很少的几个状态, 或者很少发生改变, 那么应用该模式可能会显得小题大作
使用场景:
- 如果对象需要根据自身当前状态进行不同行为, 同时状态的数量非常多且与状态相关的代码会频繁变更的话, 可使用状态模式。
- 如果某个类需要根据成员变量的当前值改变自身行为, 从而需要使用大量的条件语句时, 可使用该模式。
观察者模式(发布-订阅模式,一个对象作为主题,其他多个对象观察它的变化,并随它的变化改变自己,比如在按钮按下时执行自己的逻辑。)
它定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个主题对象。这个主题对象在状态发送变化时,会通知所有的观察者对象,使他们能够自动的更新自己。
主要包含以下角色:
- 抽象主题角色:把所有观察者对象保存在一个集合里,每个主题都可以有任意数量的观察者,抽象主题提供一个接口,可以增加和删除观察者对象。
- 具体主题角色:它将有关状态存入具体观察者对象中,在具体主题的内部状态发送变化时,给所有注册过的观察者发送通知。
- 抽象观察者角色:它定义了一个更新接口,使得在得到主题更改通知时更新自己。在绝大多数情况下, 该接口仅包含一个 update更新方法。 该方法可以拥有多个参数, 使发布者能在更新时传递事件的详细信息。
- 具体观察者角色:实现抽象观察者定义的更新接口,以便在得到主题更改通知时更新自身的状态。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
// 抽象主题角色
type Subject interface {
attach(Observer) //添加订阅者(观察者对象)
notify(message string)
}
// 具体主题角色
type SubscriptionSubject struct {
weiXinUserArr []Observer
}
func (s *SubscriptionSubject) attach(observer Observer) {
s.weiXinUserArr = append(s.weiXinUserArr, observer)
}
func (s *SubscriptionSubject) notify(message string) {
for _, v := range s.weiXinUserArr {
v.update(message)
}
}
// 抽象观察者角色
type Observer interface {
update(message string)
}
// 具体观察者角色
type WeiXinUser struct {
name string
}
func (w WeiXinUser) update(message string) {
fmt.Println(w.name + "-" + message)
}
func main() {
// 创建主题
subject := new(SubscriptionSubject)
// 客户订阅
subject.attach(&WeiXinUser{"张三"})
subject.attach(&WeiXinUser{"李四"})
// 更新内容
subject.notify("发布了新内容")
}
|
优点:
- 开闭原则。 你无需修改发布者代码就能引入新的订阅者类 (主题也一样)。
- 降低了目标与观察者之间的耦合关系,两者属于抽象耦合关系(具体主题和抽象观察者耦合)
- 被观察者发送通知,所有注册的观察者都会收到信息(可以实现广播机制)
缺点:
- 如果观察者非常多的话,那么所有的观察者收到被观察者发送的通知会花费很多时间,可以通过开携程解决
- 如果被观察者有循环依赖,那么被观察者发送通知会使观察者循环调用,导致系统崩溃。尽量不要让主题和观察者双向沟通,观察者只能收主题的消息,不能给主题发消息。
- 订阅者的通知顺序是随机的。
- 观察值模式没有相应的机制让观察者知道所观察的目标对象是怎样发生变化的。而仅仅知道观察目标发生了变化。
使用场景:
- 对象间存在一对多关系,一个对象的信息发生改变会影响其他对象,即当一个对象状态的改变后需要改变其他对象时。
- 实际对象是无法预知或者动态变化时。
- 需要在具体的对象的某种动作中注入代码逻辑,这种在界面类中最为常见,比如定义在按钮按下时执行逻辑。
- 当一个对象必须“观察”其他对象时。
中介者模式(如果结构体之间的关联过于复杂可以用这个解耦,它的最大作用就是解耦合,集中管理结构体的交流,但是如果滥用会导致中介者结构体十分庞大,维护困难,得不偿失)
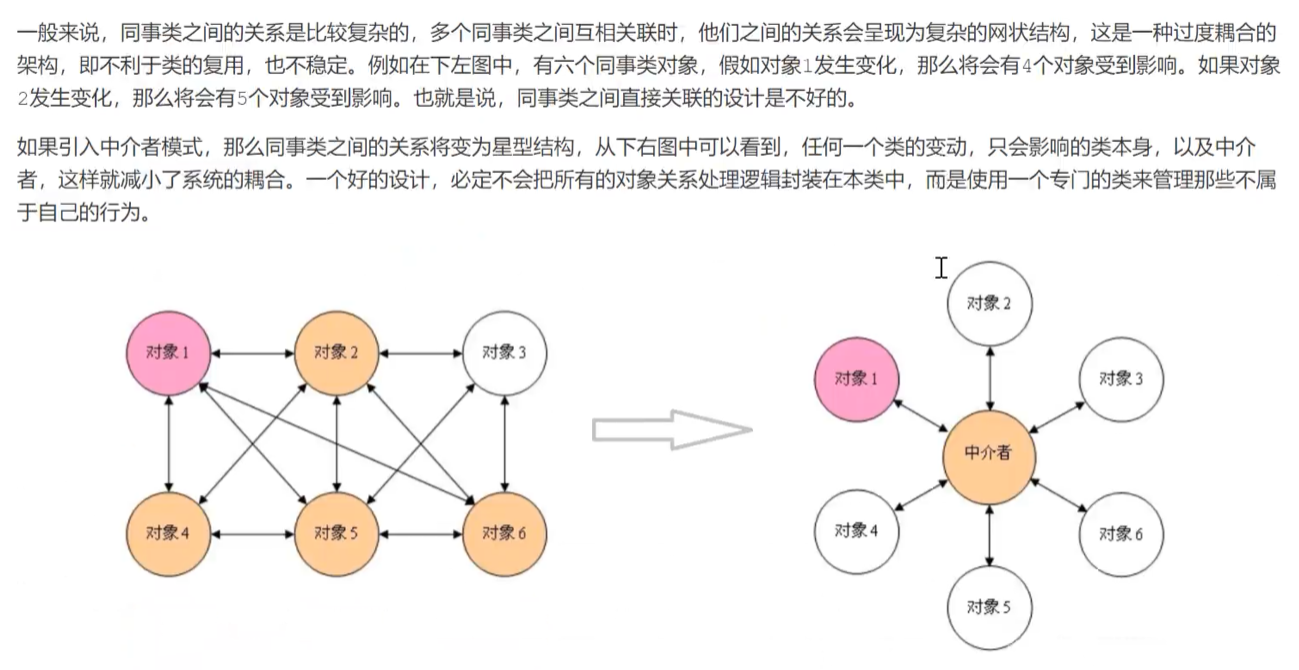
中介者模式又叫调停模式,定义一个中介角色来封装一系列对象之间的交互,使原有对象之间的耦合松散,且可以独立地改变它们之间的交互。中介者能使得程序更易于修改和扩展, 而且能更方便地对独立的组件进行复用, 因为它们不再依赖于很多其他的类。
中介者模式比较简单,就是把多个对象中的公共方法提升到中介者中完成,发送者调用中介者方法,中介者再去调用对象具体方法,体现了依赖倒置的原则。但是同事中介者模式是一个很忌讳滥用的模式,滥用之后不仅不会优化代码,反而使得中介者类十分冗余。
看样子它和代理模式有点像,但是代理模式是隐藏对象和加强对象的功能,中介者模式不是。这个模式的重点在于转发和处理对象之间的交互。
主要包含以下角色:
- 抽象中介者角色:它是中介者的接口,提供了同事对象注册与转发同事对象信息的抽象方法。
- 具体中介者角色:实现中介者接口,定义一个List来管理同事对象(管理同事类),协调各个同事之间的交互关系,因此它依赖于同事角色。
- 抽象同事类角色:定义同事类的接口,保存中介者对象(交互需要双方都存有对方的信息,不然就是单向的),提供同事对象交互的抽象方法,定义所有相互影响的同事类的公共功能。
- 具体同事类角色:是抽象同事类的实现者,当需要与其他同事对象交互时,由中介者对象负责后续的交互。
比如租房人和中介和房东的关系,租房人无法直接联系到房东,需要经过中介。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
// 抽象中介者角色
type mediator interface {
constact(string, person) //中介给某个对象发送消息,p表示发送人
}
// 具体中介者角色
type mediatorStructure struct {
houseOwner
tenant //如果只有一种结构体则可以存为切片
}
// 中介给对应对象发送数据
func (m mediatorStructure) constact(msg string, p person) {
switch p.(type) {
// 如果类型是房东,就需要将这条数据给租房人
case houseOwner:
m.tenant.getMessage(msg)
case tenant:
m.houseOwner.getMessage(msg)
}
}
// 抽象同事类角色
type person interface {
constact(string) //对象给中介发消息
getMessage(string) // 获取中介的消息
}
// 房东
type houseOwner struct {
name string
mediator
}
// 给中介发消息
func (h houseOwner) constact(msg string) {
h.mediator.constact(h.name+": "+msg, h)
}
func (h houseOwner) getMessage(msg string) {
fmt.Println("房东收到消息:" + msg)
}
// 租房人
type tenant struct {
name string
mediator
}
func (t tenant) constact(msg string) {
t.mediator.constact(t.name+": "+msg, t)
}
func (t tenant) getMessage(msg string) {
fmt.Println("租房人收到消息:" + msg)
}
func main() {
// 创建中介
mediatorStructure := mediatorStructure{}
// 租房人、房东和中介关联
tenant := tenant{
name: "张三租房",
mediator: mediatorStructure,
}
houseOwner := houseOwner{
name: "李四房东",
mediator: mediatorStructure,
}
mediatorStructure.houseOwner = houseOwner
mediatorStructure.tenant = tenant
// 发送消息
tenant.constact("我要租套一")
houseOwner.constact("没房")
}
|
中介者模式简单来说就是在对象之间加了一个新的对象,它负责对信息进行转发。发送者先把需要发送的信息发往中介,中介就像中转站,可以对收到的信息进行加工等操作,然后再发往接收者。因此中介者需要同事类的信息,同事类也要保存中介者的信息。或者说是原本应该是发送者直接调用接收者的方法,现在变成了发送者调用中介者的方法,中介者再去调用接收者的方法,多包了一层。中介者的主要目标是消除一系列系统组件之间的相互依赖
优点:
- 松散耦合。中介者模式通过把多个同事对象之间的交互封装到中介者对象里面,从而使得同事对象之间松散耦合,基本上可以做到互补依赖。这样一来同事对象就可以独立的变化和复用,而不用像以前那样迁一处而动全身了
- 集中控制交互。多个同事对象的交互被封装在中介者里面集中管理,使得这些交互行为发生变化的时候,只需要修改中介者对象就可以了,当然如果是已经做好的系统,那么扩展中介者对象,而各个同时类不需要修改。
- 一对多关联转变为一对一关联。没有使用中介者模式的时候,同事对象之间的关系通常是一对多的,引入中介者模式之后,中介者对象和同事对象的关系变成双向的一对一,这让对象的关系更容易理解和实现。
缺点:
- 当同事类太多,中介者的职责将非常大。它会变得复杂庞大,以至于系统难以维护。即一段时间后, 中介者可能会演化成为上帝对象。
- 过分滥用中介者模式会使中介者实现类十分庞大,所有的方法都需要修改中介者实现类。维护复杂。所以这个模式慎用。不应当在职责混乱的时候使用。
使用场景:
- 当一些对象和其他对象紧密耦合以致难以对其进行修改时, 可使用中介者模式。
- 当组件因过于依赖其他组件而无法在不同应用中复用时, 可使用中介者模式。应用中介者模式后, 每个组件不再知晓其他组件的情况。 尽管这些组件无法直接交流, 但它们仍可通过中介者对象进行间接交流。
- 如果为了能在不同情景下复用一些基本行为, 导致你需要被迫创建大量组件子类时, 可使用中介者模式。由于所有组件间关系都被包含在中介者中, 因此你无需修改组件就能方便地新建中介者类以定义新的组件合作方式。
迭代器模式(为复杂的聚合对象提供遍历方式,可以向上层隐藏对象的表现形式[上层只能知道结果,但是不清楚数据结构是树还是列表等],将遍历和存储功能分开来,聚合角色专注存储,迭代器专注遍历)
对复杂聚合对象遍历的一种解决方案,比如树之类的聚合,因为range只能遍历map和切片,如果有树的数据结构就没法使用range,就可以手写一套遍历方案。
提供一个对象来顺序访问聚合对象中的一系列数据,而不暴露聚合对象的内部表现形式。
不断向集合中添加遍历算法会模糊其 “高效存储数据” 的主要职责。 此外, 有些算法可能是根据特定应用订制的, 将其加入泛型集合类中会显得非常奇怪。
另一方面, 使用多种集合的客户端代码可能并不关心存储数据的方式。 不过由于集合提供不同的元素访问方式, 你的代码将不得不与特定集合类进行耦合。
迭代器通常会提供一个获取集合元素的基本方法。 客户端可不断调用该方法直至它不返回任何内容, 这意味着迭代器已经遍历了所有元素。
所有迭代器必须实现相同的接口。 这样一来, 只要有合适的迭代器, 客户端代码就能兼容任何类型的集合或遍历算法。 如果你需要采用特殊方式来遍历集合, 只需创建一个新的迭代器类即可, 无需对集合或客户端进行修改。
主要包含以下角色:
- 抽象聚合角色:定义存储、添加、删除聚合元素以及创建迭代器对象的接口。
- 具体聚合角色:实现抽象聚合类,返回一个具体迭代器的实例。
- 抽象迭代器角色:定义访问和遍历聚合元素的接口,通常包含hasNext()、next()等方法。
- 具体迭代器角色:实现抽象迭代器中所定义的方法,完成对聚合对象的遍历,记录遍历的当前位置。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
type student struct {
name string
number int
}
//抽象迭代器角色
type Iterator interface {
hasNext() bool //判断是否有下一个数据
next() *student
}
// 具体迭代器角色
type StudentIterator struct {
index int
students []*student
}
func (s *StudentIterator) hasNext() bool {
return s.index < len(s.students)
}
func (s *StudentIterator) next() *student {
if s.hasNext() {
stu := s.students[s.index]
s.index++
return stu
}
return nil
}
// 抽象聚合角色
type Aggregate interface {
CreateIterator() Iterator //创建一个迭代器
}
type StudentAggregate struct {
students []*student
}
func (s *StudentAggregate) CreateIterator() Iterator {
return &StudentIterator{
students: s.students,
}
}
func main() {
// 创建一个集合
students := make([]*student, 0)
students = append(students, &student{"张三", 001}, &student{"李四", 002}, &student{"王五", 003})
// 将集合放入聚合角色中
studentAggregate := StudentAggregate{
students: students,
}
//创建迭代器
iterator := studentAggregate.CreateIterator()
stu := iterator.next()
fmt.Println(stu)
}
|
优点:
- 它支持以不同的方式遍历一个聚合对象(遍历方式存在了具体迭代器中,可以定义新的迭代器来访问原数据),在同一个聚合对象上可以定义多种遍历方式。在迭代器模式中只需要用一个不同的迭代器来替换原有迭代器即可改变遍历算法。
- 由于引入了迭代器,在原有的聚合对象中不需要再自行提供数据遍历等方法(交由迭代器管理),简化了聚合类的设计。
- 由于引入了抽象层,增加新的聚合类和迭代器都很方便,无须修改原有代码,满足开闭原则。
- 可以暂停遍历并在需要时继续,也可以并行遍历同一个集合。
缺点:
- 增加了类的个数,一定程度上增加了系统的复杂性。
- 如果你的程序只与简单的集合进行交互, 应用该模式可能会矫枉过正。
- 对于某些特殊集合, 使用迭代器可能比直接遍历的效率低。
使用场景:
- 当需要为聚合对象提供多种遍历方式时。
- 当需要为遍历不同的聚合结构提供一个统一的接口时。
- 当访问一个聚合对象的内容无须暴露其内部细节的表示时。
- 当集合背后为复杂的数据结构, 且你希望对客户端隐藏其复杂性时 (出于使用便利性或安全性的考虑), 可以使用迭代器模式。迭代器封装了与复杂数据结构进行交互的细节, 为客户端提供了多个访问集合元素的简单方法。 这种方式不仅对客户端来说非常方便, 而且能避免客户端在直接与集合交互时执行错误或有害的操作, 从而起到保护集合的作用。
访问者模式(解决不同角色调用成员结构体元素方法时有不同情况的问题,解决复杂结构体结构不变但成员变量操作处理逻辑易变的问题,把对数据的操作都封装到访问者类中,我们只需要调用不同的访问者,而无需改变结构类。平时工作中很少使用到这种模式)
封装一些作用于某种数据结构中的各元素的操作,它可以在不改变这个数据结构的前提下定义作用于这些元素的新的操作。
访问者模式是一种将数据操作与数据结构分离的设计模式,它是 《设计模式》中较为复杂的一个,但它的使用频率并不高,正如《设计模式》的作者 GOF 对访问者模式的描述:大多数情况下,你并不需要使用访问者模式,但是当你一旦需要使用它时,那你就是真正的需要它了。
访问者模式的基本思想是,软件系统中拥有一个由许多对象构成的、比较稳定的对象结构,这些对象的类都拥有一个 accept 方法用来接受访问者对象的访问。访问者是一个接口,它拥有多个 visit 方法(参数不同,在golang中表现为该访问者针对不同成员结构体有不同的解决方案),这个方法对访问到的对象结构中不同类型的元素做出不同的处理。在对象结构的一次访问过程中,我们遍历整个对象结构,对每一个元素都实施 accept 方法,在每一个元素的 accept 方法中会调动访问者的 visit 方法,从而使访问者得以处理对象结构的每一个元素,我们可以针对对象结构设计不同的访问者类来完成不同的操作,达到区别对待的效果。
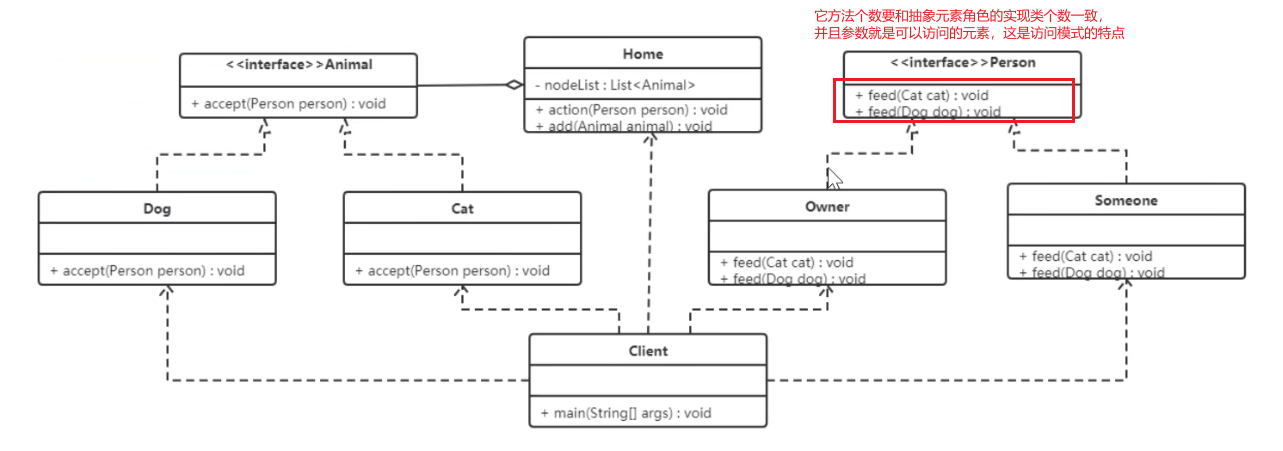
包含以下角色:
- 抽象访问者角色:定义了对每一个元素访问的行为,它的参数就是可以访问的元素,它的方法个数理论上来讲与元素类个数是一样的(抽象元素角色的实现类的个数),从这点不难看出,访问者模式要求元素类的个数不能改变。
- 具体访问者角色:给出对每一个元素类访问时所产生的具体行为。
- 抽象元素角色:定义了一个接受访问者的方法,其意义是指,每一个元素都要可以被访问者访问。
- 具体元素角色:提供接受访问方法的具体实现,而这个具体的实现,通常情况下是使用访问者提供的访问该元素类的方法。
- 对象结构角色:定义当中所提到的对象结构,对象结构是一个抽象表述,具体点可以理解为一个具有容器性质或者复合对象特性的类,它会含有一组元素,并且可以迭代这些元素,供访问者访问。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
// 抽象元素角色
type animal interface {
accept(person)
}
// 具体元素角色
type dog struct {
}
func (d dog) accept(p person) {
p.doDog(d)
fmt.Println("狗的接受接口")
}
type cat struct {
}
func (c cat) accept(p person) {
p.doCat(c)
fmt.Println("猫的接受接口")
}
// 抽象访问者角色
type person interface {
doDog(d dog)
doCat(d cat)
}
// 具体访问者角色
type owner struct {
}
func (o owner) doDog(d dog) {
fmt.Println("主人控制狗")
}
func (o owner) doCat(d cat) {
fmt.Println("主人控制猫")
}
type someOne struct {
}
func (s someOne) doDog(dog) {
fmt.Println("其他人控制狗")
}
func (s someOne) doCat(cat) {
fmt.Println("其他人控制猫")
}
// 对象结构角色
type Home struct {
animal []animal
}
func (h *Home) action(p person) {
for _, v := range h.animal {
v.accept(p)
}
}
func main() {
// 创建home对象
home := Home{
animal: make([]animal, 0),
}
// 添加元素
home.animal = append(home.animal, dog{}, cat{})
home.action(owner{})
}
|
优点:
- 扩展性好。在不修改对象结构中的元素的情况下,为对象结构中的元素添加新的功能(只需要增加新的访问者来专门针对这个功能即可)。
- 复用性好。通过访问者来定义整个对象的结构通用的功能,从而提高复用程度。
- 分离无关行为。通过访问者来分离无关的行为,把相关的行为封装在一起,构成一个访问者,这样每一个访问者的功能都比较单一
缺点:
- 对象结构变化困难。每增加一个新的元素类,都要在每一个具体访问者类中增加相应的具体操作,这违背了开闭原则
- 违反了依赖倒置原则。访问者模式依赖了具体类,而没有依赖抽象类。
- 从本质来说,访问者模式中元素角色只有accept方法来调用访问者中的具体方法,这导致如果一个元素有两个方法的话,必须要新增一个访问者来针对这个新的方法,这会导致访问者的职责混乱,有些表示不同访问者,有些又表示同一访问者访问元素的不同方法。
使用场景:
- 对象结构相对稳定,但其操作算法经常变化的程序。(此时就可以将操作包到访问者类中,抽象访问者定义的是大概操作,而可以定义不同的具体访问者来表示不同的操作)
- 对象结构中的对象需要提供多种不同且不相关的操作,而且要避免让这些操作的变化影响对象结构。
备忘录模式(用于对象的备份,当你需要创建对象状态快照来恢复其之前的状态时, 可以使用备忘录模式)
备忘录模式提供了一种状态恢复的实现机制,使得用户可以方便的回到一个特定的历史步骤,当新的状态无效或存在问题时,可以使用暂时存储起来的备忘录将状态复原,很多软件都提供了撤销操作,如Word、记事本、数据库或操作系统的备份、棋类游戏的悔棋功能都属于这一类。
又叫快照模式,在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个当前状态,以便以后当需要时能将该对象恢复到原先保存的状态。
主要包含以下角色:
- 发起人角色:记录该对象当前时刻的内部状态信息,提供创建备忘录和恢复备忘录数据的功能,实现其他业务功能,它可以访问备忘录里的所有信息。
- 备忘录角色:负责存储发起人的内部状态,在需要的时候提供这些内部状态给发起人。
- 管理者角色:对备忘录进行管理,提供保存与获取备忘录的功能,但其不能对备忘录的内容进行访问与修改。
备忘录有两个等效的接口:
- 窄接口:管理者对象(和除发起人对象之外的任何对象)看到的是备忘录的窄接口,这个窄接口只允许他把备忘录对象传给其他的对象(只能获取备忘录对象,不能对备忘录对象里面的元素访问和修改)。
- 宽接口:与管理者看到的窄接口相反,发起人对象可以看到一个宽接口,这个宽接口允许他读取所有的数据,以便根据这些数据恢复这个发起人对象的内部状态。
优缺点:
- 提供了一种可以恢复状态的机制。当用户需要时能够比较方便地将数据恢复到某个历史状态。
- 实现了内部状态的封装。除了创建它的发起人之外,其他对象都不能够访问这些状态信息(黑箱备忘录模式)。
- 简化了发起人的职责。发起人不需要管理和保存其内部状态的各个备份,所有状态信息都保存在备忘录中,并由管理者进行管理,这符合单一职责原则。
- 可以在不破坏对象封装情况的前提下创建对象状态快照。
缺点:
- 资源消耗大。如果要保存的内部状态信息过多或特别的频繁,将会占用较多的内存资源。
- 负责人必须完整跟踪发起人的生命周期, 这样才能销毁弃用的备忘录。
使用场景:
- 需要保存和恢复数据的场景,如玩游戏时的中间结果的存档功能。
- 需要提供一个可回滚操作的场景。如word撤销,数据库事务操作等。
白箱备忘录模式
备忘录角色对任何对象都提供一个接口,即宽接口,备忘录角色的内部所存储的状态对所有对象公开(违背了备忘录模式的窄接口概念)。
案例:游戏挑战BOSS,并且可以恢复到决斗前
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
// 发起人对象,即要存进备忘录中的对象;游戏角色类
type gameRole struct {
hp int
mp int
}
// 初始化内部状态
func (g *gameRole) initState() {
g.hp = 100
g.mp = 100
}
// 开战
func (g *gameRole) fight() {
g.hp = 40
g.mp = 0
}
// 保存角色状态
func (g *gameRole) saveState() *roleStateMemento {
return &roleStateMemento{
hp: g.hp,
mp: g.hp,
}
}
// 恢复角色状态
func (g *gameRole) recoverState(r *roleStateMemento) {
// 将备忘录对象中存储的角色状态赋值给当前角色
g.hp = r.hp
g.mp = r.mp
}
func (g *gameRole) stateDisplay() {
// 展示角色信息
fmt.Printf("hp:%v --mp:%v\n", g.hp, g.mp)
}
// 备忘录对象,保存发起人对象数据
type roleStateMemento struct {
hp int
mp int
}
// 备忘录对象管理者角色
type roleStateCaretaker struct {
*roleStateMemento
}
func main() {
fmt.Println("-------开战前----")
// 初始化角色
gameRole := gameRole{}
gameRole.initState()
gameRole.stateDisplay()
// 保存状态
roleStateCaretaker := roleStateCaretaker{
roleStateMemento: gameRole.saveState(),
}
fmt.Println("-------开战后----")
gameRole.fight()
gameRole.stateDisplay()
fmt.Println("-------回滚----")
gameRole.recoverState(roleStateCaretaker.roleStateMemento)
gameRole.stateDisplay()
}
|
白箱备忘录模式是破坏了封装性的,其中任何对象都可以访问备忘录角色 roleStateMemento,任何对象都可以对其进行赋值修改。
黑箱备忘录模式
备忘录角色对发起人提供一个宽接口(在发起人中定义一个内部的备忘录角色,并在保存备忘录角色时同时赋值),而为其他对象提供一个窄接口(定义一个备忘录角色的接口,外部只能获取接口,无法获取具体结构体)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
|
// 发起人对象,即要存进备忘录中的对象;游戏角色类
type gameRole struct {
hp int
mp int
*roleStateMemento
}
// 初始化内部状态
func (g *gameRole) initState() {
g.hp = 100
g.mp = 100
}
// 开战
func (g *gameRole) fight() {
g.hp = 40
g.mp = 0
}
// 保存角色状态
func (g *gameRole) saveState() memento {
// 发起人可以直接通过访问内部元素的方法修改和访问备忘录角色,而其他角色无法获取到
g.roleStateMemento = &roleStateMemento{
hp: g.hp,
mp: g.hp,
}
return g.roleStateMemento
}
// 恢复角色状态
func (g *gameRole) recoverState(r memento) {
// 将备忘录对象中存储的角色状态赋值给当前角色
hp, mp := r.getHpAndMp()
g.hp = hp
g.mp = mp
}
func (g *gameRole) stateDisplay() {
// 展示角色信息
fmt.Printf("hp:%v --mp:%v\n", g.hp, g.mp)
}
// 黑箱最重要的点就是给备忘录定义一个接口,让备忘录对象实现它,这样管理者角色和其他角色就无法直接获取和修改备忘录中的数据
type memento interface {
getHpAndMp() (int, int)
}
// 备忘录对象,保存发起人对象数据
type roleStateMemento struct {
hp int
mp int
}
func (r roleStateMemento) getHpAndMp() (int, int) {
return r.hp, r.mp
}
// 备忘录对象管理者角色
type roleStateCaretaker struct {
memento
}
func main() {
fmt.Println("-------开战前----")
// 初始化角色
gameRole := gameRole{}
gameRole.initState()
gameRole.stateDisplay()
// 保存状态
roleStateCaretaker := roleStateCaretaker{
memento: gameRole.saveState(),
}
fmt.Println("-------开战后----")
gameRole.fight()
gameRole.stateDisplay()
fmt.Println("-------回滚----")
gameRole.recoverState(roleStateCaretaker.memento)
gameRole.stateDisplay()
}
|
解释器模式(使用场景较少,开发一种简单的解释器来处理某种特定的规则,定义的规则可以成为一个语法树,采用递归或循环来实现。场景有规则引擎、自定义语法、sql解析等,就是将一堆字符串解释成golang的代码)
给定一个语言,定义它的文法表示,并定义一个解释器,这个解释器使用该标识来解释语言中的句子。在解释器模式中,我们需要将待解决的问题提取出规则,抽象为一种语言。比如加减法运算的规则就是由数值和符号组成的合法序列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
// 环境类,存储公用数据
type contexts struct {
expr map[variable]int
}
// 抽象表达式类
type AbstractExpression interface {
interpret(contexts) int
}
// 变量类,终结符表达式
type variable struct {
name string
}
func (v *variable) interpret(c contexts) int {
// 直接返回变量的值
return c.expr[*v]
}
// 加法表达式,非终结符表达式
type plus struct {
left AbstractExpression
right AbstractExpression
}
func (p *plus) interpret(c contexts) int {
// 将左边表达式和右边表达式相加
return p.left.interpret(c) + p.right.interpret(c)
}
type minus struct {
left AbstractExpression
right AbstractExpression
}
func (m *minus) interpret(c contexts) int {
// 将左边表达式和右边表达式相减
return m.left.interpret(c) - m.right.interpret(c)
}
func main() {
// 创建环境对象
contexts := contexts{
expr: make(map[variable]int),
}
contexts.expr[variable{"a"}] = 1
contexts.expr[variable{"b"}] = 2
contexts.expr[variable{"c"}] = 3
contexts.expr[variable{"d"}] = 4
// 计算a+b-c+d,递归调用会先计算最里面的,因此需要先把b-c计算出来
expr := plus{
left: &variable{"a"},
right: &plus{
left: &variable{"d"},
right: &minus{
left: &variable{"b"},
right: &variable{"c"},
},
},
}
fmt.Println(expr.interpret(contexts))
}
|
优缺点:
- 易于改变和扩展文法。由于在解释器模式中使用类来表示语言的文法规则,因此可以通过继承等机制来改变和扩展语法。每一条文法规则都可以表示为一个类,因此可以方便地实现一个简单的语言。
- 实现文法较为容易。在抽象语法树中每一个表达式节点类的实现方式都是相似的,这些类的代码编写都不会特别复杂。
- 增加新的解释器表达式较为方便,增加一个终结或非终结式表达式即可,原有表达式类代码无须修改,符合开闭原则。
缺点:
- 对于复杂文法难以维护。在解释器模式中,每一条规则至少需要定义一个类,因此如果一个语言包含太多文法规则,类的个数将会急剧增加,导致系统难以管理和维护。
- 执行效率较低。由于在解释器模式中使用了大量的循环或递归调用,因此在解释较为复杂的句子时其速度很慢,而且代码的调试过程也比较麻烦。
- 可使用场景少。
使用场景:
- 当语言的文法较为简单,且执行效率不是关键问题时。
- 当问题重复出现,且可以用一种简单的语言来进行表达时。
- 当一个语言需要解释执行,并且语言中的句子可以表示为一个抽象语法树的时候。