Go从语言层面就支持了并发,虽然并发程序的内存管理是非常复杂的,但是GO提供了自动垃圾回收机制
并行和并发的区别:并行指在同一时刻有多条指令在多个处理器上同时进行,并发指虽然在单个处理器上同一时刻只能有一条指令执行,但多个进程指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果
goroutine(协程)

通常main函数在一个单独的协程中运行,成为主协程,新的goroutine用go语句来创建,称为子协程,如果主协程中有for死循环,子协程要在死循环前建立,否则一直死循环就无法运行到创建子协程的语句

注意:主协程退出后,子协程会同时跟着退出
runtime包
Gosched()

Gosched()的作用就像linux中的进程优先级一样,但是如果在A协程中添加了runtime.Gosched()后,A协程会搁置到其他协程完成任务退出协程后再继续进行A协程
Goexit()
调用runtime.Goexit()将立即终止当前协程的进行,即使写在协程中的调用函数里也会中止当前协程
GOMAXPROCS()
调用runtime.GOMAXPROCS()用来设置 可以并发计算 的CPU核数的最大值,并返回之前的值
n := runtime.GOMAXPROCS(4) //以四核并发计算,核数可以大于当前系统的最大核数
channel类型

定义了两个函数person1和person2,虽然协程是同时进行的,但是两个公用了一个公共资源,最后打印就会出现这边打印一个字母那边打印一个,就造成了资源竞争问题。channel属于引用传递,即调用的都是同一个channel。
如果在person2中设置channel堵塞,它就会让此进程一直堵在channel步骤,而person1中先调用公共资源,person2暂停,当person1资源调用完毕后将int=666传入ch,子进程1结束,ch管道中有内容了不再堵塞,此时person2中的同一个ch管道将int传入函数并丢弃,然后继续执行后面的代码来调用公共资源,这样就可以避免资源竞争问题。
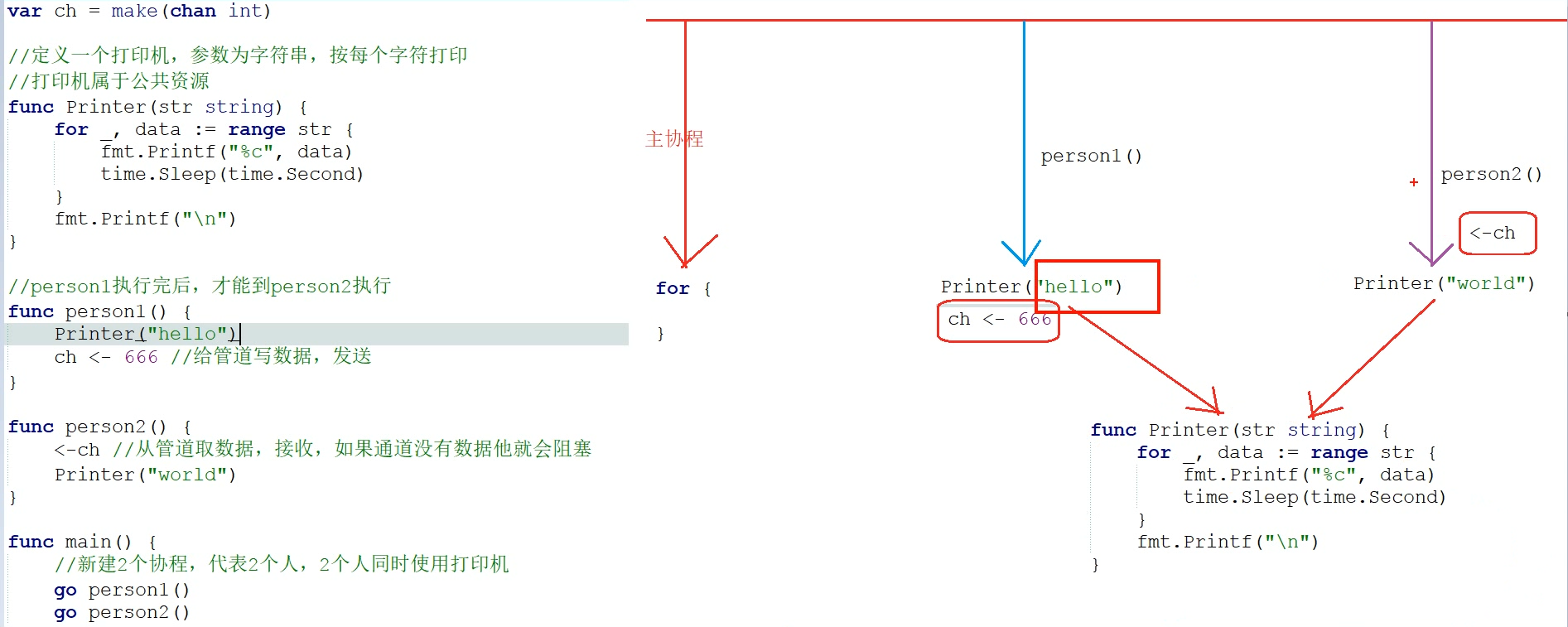
如果希望在子协程工作完成后再关闭主协程的话(主协程关闭会导致子协程同时关闭),可以在子协程中设置管道 ch<- “子协程完毕”,然后主协程接受这段内容并丢弃( <-ch ),这样就可以实现子协程没有进行到发送信息到管道那一步时,主协程ch永远堵塞,只有完成子协程任务并关闭后,主协程channel才有信息不堵塞,然后才可以正常完成主协程(channel也可以用于发送接受数据,类似linux的竖线管道)
无缓存通道和有缓存通道
channer分为无缓存通道和有缓存通道,无缓存channel没有接收或者没有发送都会造成堵塞,有缓存值的在写满缓存时就会造成堵塞,通道中没值时也无法取数据

有缓存cannel属于异步处理,每当接收者从cannel取出一条数据时,cannel中就会丢弃这条数据,将空间闲置出来给新的数据使用,当数据取完或写满时就会造成阻塞

close(ch)可以关闭通道,接收者可以通过 value,ok := <-ch来获取值,value为管道中的数据,ok在当管道没有关闭时为true,管道关闭了则为false
无缓冲通道是指在接收前没有能力保存任何值得通道。
这种类型的通道要求发送goroutine和接收goroutine同时准备好,才能完成发送和接收操作。如果两个goroutine没有同时准备好,通道会导致先执行发送或接收操作的goroutine阻塞等待。 这种对通道进行发送和接收的交互行为本身就是同步的,其中任意一个操作都无法离开另一个操作单独存在。
有缓冲通道指通道可以保存多个值。
如果给定了一个缓冲区容量,那么通道就是异步的,只要缓冲区有未使用空间用于发送数据,或还包含可以接收的数据,那么其通信就会无阻塞地进行
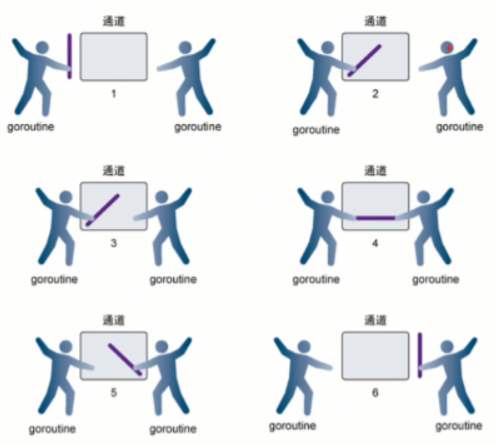
上图所示:
- 右侧的goroutine正在从通道接收一个值。
- 右侧的goroutine独立完成了接手值得动作,而左侧的goroutine正在发送一个新值到通道里。
- 左侧的goroutine还在向通道发送新值,而右侧的goroutine正在从通道接收另一个值。这个步骤里的两个操作既不是同步,也不会互相阻塞。
- 所有的发送和接收都完成,而通道里还有几个值,也有一些空间可以存储更多的值
无缓冲的与有缓冲channel有着重大差别,那就是一个是同步的 一个是非同步的。
|
|
无缓冲: 不仅仅是向 c1 通道放 1,而是一直要等有别的携程 <-c1 接手了这个参数,那么c1<-1才会继续下去,要不然就一直阻塞着。 有缓冲: c2<-1 则不会阻塞,因为缓冲大小是1(其实是缓冲大小为0),只有当放第二个值的时候,第一个还没被人拿走,这时候才会阻塞。
单项channel管道

双向channel可以隐式的转换为单向channel ( var writeCan chan<- int = ch ),单向无法转换为双向
案例:
channel可以通过range来依次读取通道内的数据,它的参数只有num,并非两个值。且必须搭配close(ch)使用,不然继续迭代下去,没有值但是还在进行<-ch,这会造成通道阻塞,出现死锁问题。在写入channel的函数中最后加上 close(ch) 就可以给它发送一个信号,它会在将数据全部写入channel后关闭管道,关闭一个已经关闭的channel会导致panic,当对一个关闭后的通道进行取值直到取完后,再进行取值返回的就是类型零值,如int返回的是0
对一个已经关闭的管道是可以继续取值的,但是取到的值是对应类型的零值,如果管道没关闭继续取值就会造成死锁
|
|
由于channel属于引用传递,所以虽然函数的参数是单项通道,但是最终修改的依然是本来的双向通道ch,这可以避免在函数中又读又写造成逻辑混乱
Select (可以监听channel通道的数据流动)
注意:select如果任意某个通信可以进行,它就执行,其他被忽略。如果同时有多个case满足,它会随机选择一个,都没有满足时会阻塞等待(避免造成饥饿,因为如果某个case一直被满足,它之后的case偶尔满足,我们不能每次都让首个case通过,这样会造成后面的case长期得不到资源的分配)

注意:如果写了default,即每次都能判定成功,会导致select语句完成判定然后结束,不写就会(一直)阻塞直到case判定成功执行某一个case语句然后结束
如果select语句不加for循环,那么它只会判定一次并只将数据写入一次管道,监听一次就结束显然不符合监听的目的,所以需要往select外套一个for死循环来实现监听操作
第二个case语句,写入通道的操作必须要有一个读的操作(<-chan2)可以接收它的数据,只有写没有读是不能写成功的,有读没写也是不能读成功,都会造成管道死锁问题,这样就可以通过select实现在外部写入,select中的case读操作就判断成功。
注意:case不止是判断,它判断后面的语句能否读写成功,那么在判断成功的同时它也会往通道中读写数据
斐波那契数列
|
|
如果select语句不加for循环,那么它只会判定一次并只将数据写入一次管道,而fibonacci函数处于主协程,当判定成功后就会直接完成主协程,那么子协程也会退出,后面的数据都无法继续输出
用select实现超时退出
|
|
当ch中没有数据时,case ch会堵塞,然后三秒后case time会有数据,执行case2,往quit管道中写入数据,最下面的读取quit就不会堵塞,程序就会继续执行,如果不希望主程序结束,可以将quit管道放到一个子协程中(且主程序有for循环之类的不会结束),那么三秒后子协程运行完自动退出,不会波及主协程
注意:case语句是会执行之后的语句的,所以time.NewTimer()会在3s后继续有值,且会再输出fmt,然后此时quit管道没接收者,会一直堵塞在这里,子协程会一直存在直到主协程关闭,所以加上return语句让它在第一次就关闭此函数,或者break跳出for循环