包的导入
go语言中导入包是从 $GOPATH/src/后开始计算的,使用 /进行路径分隔。Go语言中禁止循环导入包(A导B,B导C,C导A),原因看此连接,https://www.jianshu.com/p/ea76c0d1b609,禁用虽然会导致写代码的时候麻烦点,但是可以让依赖整洁,开发高效。
包名可以自定义,ca "github.com/calc"
在Go语言程序执行时导入包语句会自动触发包内部 init()函数的调用。需要注意的是: init()函数没有参数也没有返回值。 init()函数在程序运行时自动被调用执行,不能在代码中主动调用它。运行自己的包也会执行自己的init函数,可以借此使用匿名包来只调用init函数,多用于自动加载配置文件等情况
iota常量自动生成
const() 括号中的为一个常量组,后一个不赋值默认与上一行值相同,因此可以只写一个iota
iota是常量的自动生成器,他每新增一行常量声明(即使新增的不是Iota)就自动累加1,只适用于常量,const出现的时候iota被置为0,如果iota第一次使用不是在const的第一行,如它在第五行,那iota第一次的值就为4



如果c3不赋值为iota,那它的值为100(和上一行值相同)
如果下面重新定义const内的iota,它会重置为0,也可以只写一个iota

如果是同一行,值就都一样
«表示把1左移十位,后面接0,即kb等于1然后十个0,但这是二进制,转换为十进制就是1024,mb就是移20位,就是1024*1024,即为1M
for、函数别名、匿名函数、指针
go语言在switch语句中默认保留了break,但是默认是不用写的


golang中函数名首字母大写表示公有的,小写表示私有的

可以由此实现多态

如果有多个defer,遵循先进后出原则,即先定义的defer在最后输出,defer由最下面的defer语句开始向上执行直到第一个defer语句,中间如果有defer执行失败,后面的defer语句依然会继续执行,但是如果main函数中有非defer语句执行失败导致脚本退出,那就无法继续执行后面的defer语句和普通语句



go有自动的垃圾回收机制,我们只需要创建内存即可。
数组
数组比较只支持等于和不等于,比较的是两个数组的每一个元素是否都一样,且比较的两个数组类型要一样
二维数组定义则为
当数组通过函数传递过去后,如果在主函数中没有值可以接收return的话,它就会释放,即传过去的值无论怎么修改都和主函数中的数组没关系
如何将数组通过地址传递呢?
首先方法的参数为(a *[5]int),这样就可以将数组的指针实参传递给方法,然后操作原数组的某一个下标值就可以使用 ( *a)[3]=22来改变原数组某个下标值,*a必须要用圆括号合成一个整体
随机数产生
切片
array := [5]int{1,2,3,4,5}
slice := array[1:3:5]
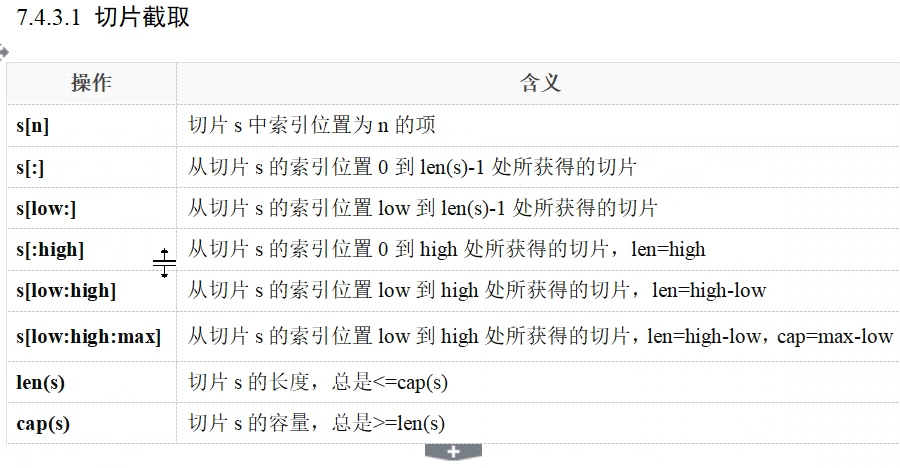
其中第一个数表示从数组的下标几开始切(下标的起点);第二个数表示为从何处结束(下标的终点,不包括此下标),切边的长度为第二个数减去第一个数,遵循左闭右开原则;第三个数可以自己定义,最小等于第二个数(即容量等于长度),不写默认为父级(被切的那个数组或切片)的len(),容量为第三个数减去第一个数

切片和数组的区别:
数组[]里面的长度是一个固定的常量,设定后便不能进行修改;
a := [5]int{} (现在数组元素为5个0)
切片,[]里面为空或者为…,切片的长度可以不固定,可以通过append方法给切片末尾追加一个成员
s := []int{} ({}中没有值,0元素,也可以像数组一样进行添加{1,2,3})
s=append(s,11)
所以可以根据[]的值来判断是切片还是数组
切片与底层数组的关系(重要):
对一个数组或切片进行切片操作后,它并不是和数组传参一样拷贝一个新数组使用,如果在新切片中对某个值重新定义,它会反映到最初那个数组或切片中
切片copy的作用为将一个切片复制到另一个切片,对应下标,不会改变容量,即如果参数交换,最终也是{6,6},使用copy是因为如果直接使用等号最后操作的依然是初始切片
map
map是无序的键值对,可以通过range进行遍历,range还可以用于数组切片等
1
2
3
4
5
6
7
8
9
10
11
|
map定义:
m :=map[int]string{1:"value",2:"value1"}
m :=make(map[int]string,10) #10为长度
map赋值:
m["key"]="value"
map删除:
delete(m,1) #删除key为1的内容
map作为函数参数传过去时属于引用传参,即在函数中修改了map的值,原值也会修改(切片也是)
|
结构体类型(多个变量合成一个变量)

也可以用s1.name=“mike"来进行部分成员初始化或者获取成员的值

这样就可以和Java操作对象一样使用,虽然new返回的是一个内存指针,但是在结构体类型中*p2.id和p2.id指向的都是同一块内存,所以可以直接p2.id来对新申请的结构体成员赋值
同一个结构体的不同变量可以进行赋值以及 等于和不等于的比较(它会比较两者每一个成员是否相等)
结构体的函数传参属于值传递,它在另一个函数中值改变并不会影响到本函数的值
引用传参才会对同一个值进行修改,如果要改为引用传参,则需要使用指针*和&进行指针传递
go语言只分为可见和不可见,当函数名、结构体、结构体成员名首字母为大写时,它为可见的,其他包可以进行调用,调用方法为包名.函数名、包名.结构体名,如果首字母为小写则只有自己包内的其他文件可以调用
匿名字段(类似java中的继承)

对于父级的变量部分初始化首先需要子集中的名字Person,然后是修改父级中的某一个成员,需要再加一个Person
我比较喜欢用st :=st{}先进行初始化(或者用var st student先声明),然后再用st.name(可以直接调用父级的元素)来进行赋值
也可以用st.Person=Person{“go”,18}或者st.Person.name这种来对父级元素进行赋值
如果父级和子级有同名成员(如name),那么就根据就近原则,默认调用的为子级的name成员,想调用父级的name就需要用显式调用 st.Person.name来赋值
当使用type定义了一个普通类型的别名后,用别名定义的变量和普通类型定义的变量是不同的类型,go将他们认作两个不同的类型
方法(类似java封装)
这样就可以通过定义的结构体元素(甚至是普通类型起别名后)调用属于它的方法,只要定义了一个对应类型的变量,就可以调用这个类型的方法(就和java中new一个新对象一样),但是方法实际上依然是函数,所以如果对象是结构体或数组,它传参依然是值传参,可以通过对方法中绑定的实例设置为实例的指针来进行引用传参
接收者类型本身不能是指针,*int之类的可以使用,但是如果在其他地方定义别名 type long *int,再将此long作为接收者的话就不能编译通过
只要接收者类型不一样,就算方法同名也属于不同方法
方法集
即一个变量或变量指针调用方法不受接收者类型的约束,只要接受者类型是同种自定义类型的值或者指针都可以进行调用(它在执行方法时,内部会先自动将指针转换成变量或者反之)
方法的继承和重写
子级不仅可以继承父级的结构体成员,还会继承父级的方法(直接调用就行)
重写就是将接收者改为子级的自定义函数,其他参数和变量名相同,go语言会采用就近原则,先调用同作用域的方法,如果同作用域没有该方法就会调用父级的,如果需要调用父级的方法,可以采用显式调用,st.Person.PrintInfo()
方法值:保存方法的入口地址。调用方法时无需再传递接收者,因为它已经隐藏了接受者 pFunc := p.SetInfo(),下次直接pFunc()就可以直接调用
方法表达式:通过自定义类型来显式的把接收者传递过去,pFunc := (Person).SetInfo,调用的时候就可以使用pFunc(p)来进行调用,这里p变量可以指针和变量通用,但是Person必须和方法对应,方法是指针就需要输入 *Person
接口

接口命名习惯以er结尾,只有方法声明,没有实现也没有数据字段,但是方法是可以添加参数的
然后在main函数中声明一个接口类型,var i Humaner,然后让 i 等于其他接收者的自定义类型,当 i 等于某个接收者类型它就会调用那个类型的同名方法,但是i等于其他接收者时,i只能调用属于i接口的方法,专属于接收者的方法以及其变量,接口都不能调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
//定义接口类型
type Hunmaner interface {
sayhi()
}
//定义学生结构体类型
type student struct {
name string
id int
}
//定义学生方法
func (student) sayhi() {
fmt.Println("student say hi")
}
//定义老师结构体类型
type teacher struct {
name string
addre string
}
//定义老师方法
func (teacher) sayhi() {
fmt.Println("teacher say hi")
}
//实现多态,定义一个接口的方法,方法参数为接口类型,将其他接收者类型的实参传进去就可以实现调用不同方法
func whoSayhi(i Hunmaner){
i.sayhi()
}
func main() {
//i等于学生结构体,i就可以调用学生的方法
var i Hunmaner
i = student{name: "mike"}
i.sayhi()
//输出学生方法中的语句
//通过接口实现不同的方法
whoSayhi(student{name: "mike"})
i = teacher{name: "laoshi"}
i.sayhi()
//输出老师方法中的语句
}
|
也可以通过切片同时实现多种接收者的同名的方法
接口也可以实现继承(使用匿名字段),当定义一个Personer变量时,它可以调用父级的sayhi()方法也可以调用自身的sing()方法
父级可以等于子级的值,反过来则不可以(由多的向少的转换),如 定义一个父级i,让i等于子级iPro,i=iPro是可以的,注意语法是 父级=子级,这个作用于设置子级的值,然后将子级的值赋给父级使用,父级只能使用属于父级的方法,子级的方法无法使用
如何判断一个空接口变量中值的类型(value.(int))
,ok模式常用于测试map的对应key是否有值,有值ok为ture,没有则为false,value用于存放为true时的值,为false时为空
1
2
|
i := map[int]string{1: "a"}
value, ok := i[1]
|
还有另外五种用法(https://zhuanlan.zhihu.com/p/129220255)
有一种用法是判断空接口类型变量的type(切片和数组无法使用这个,因为它们两个在定义之初就已经确定了类型)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
i := make([]interface{}, 3)
i[0] = 1
i[1] = "str"
i[2] = stu{"mike"}
for _, deta := range i {
if value, ok := deta.(int); ok == true {
fmt.Println("这是一个整型", value)
} else if value, ok := deta.(string); ok == true {
fmt.Println("这是一个字符串", value)
} else if value, ok := deta.(stu); ok == true {
fmt.Println("这是一个结构体类型", value)
}
}
//也可以使用switch方法,用此方法时括号中为type
for _, deta := range i {
switch value := deta.(type) {
case int:
fmt.Println("这是一个整型", value)
case string:
fmt.Println("这是一个字符串", value)
case stu:
fmt.Println("这是一个结构体类型", value)
}
}
|
error错误接口的应用(错误抛出,不致命错误使用这种)
在工作中error常用于普通错误,这样可以自建一个错误信息抛出,error是默认值为nil (空值)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
//要先导入包errors,import "errors"
func Mydiv(a, b int) (result int, err error) {
if b == 0 {
err = errors.New("分母不能为0")
} else {
result = a / b
}
return
}
func main() {
result, err := Mydiv(10, 0)
fmt.Println(result) //值为默认值0
fmt.Println(err) //值为自己定义的错误值
}
|
panic错误接口的调用(致命错误)
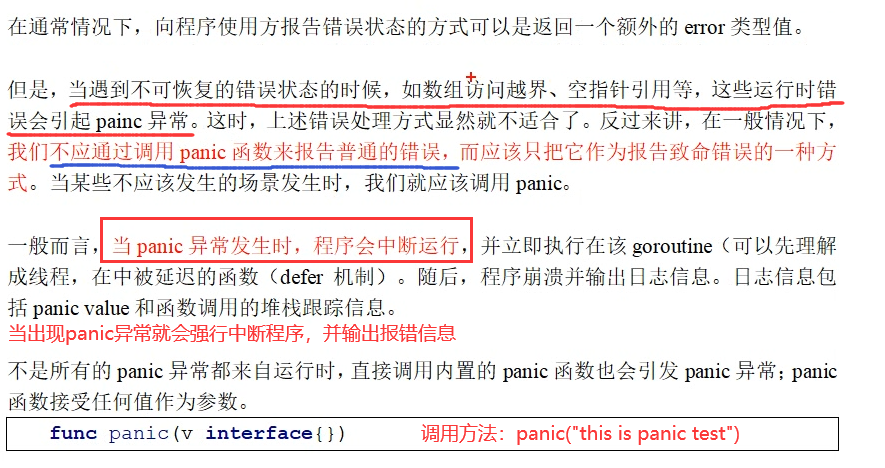
自己调用panic属于显式调用,但在数组越界,空指针引用等情况发生时,go也会抛出panic异常,因为它有自己隐式调用了默认定义的panic异常
recover错误接口的调用(拦截panic异常,恢复程序运行流程)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
func test01(x int) {
//使用数组下标越界生成panic异常
//recover必须和defer一起存在,recover()会拦截panic异常并返回panic的异常信息
//如果未发生panic异常,recover()会返回一个nil
//程序会继续运行,但是出错的函数会跳过
defer func() {
if err := recover(); err != nil {
fmt.Println(err)
}
}()
var a [10]int
a[x] = 111
}
func test02() {
fmt.Println("正常输出的一个方法")
}
func main() {
test01(11)
test02()
}
运行结果:
runtime error: index out of range [11] with length 10
正常输出的一个方法
|
文本和文件处理
字符串处理
字符串操作:(需要导入包strings)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
Contains(查看是否包含某一字串,包含返回true)
strings.Contains("hello", "he")
Join(字符串拼接,参数为一个切片和一个string,返回结果为he@ta@ssss)
s := []string{"he", "ta", "ssss"}
fmt.Println(strings.Join(s, "@"))
Index(在字符串s中查找sep所在的位置,返回位置值,找不到返回-1,如果ken第二个值为t,返回的就是-1)
strings.Index("chicken","ken") 返回4
Repeat(重复字符串n次,最后返回重复的字符串)
strings.Repeat("na",2)
Replace(替换,2表示替换几个,-1表示全部替换)
strings.Replace("ok ok ok","k","t",2)
Split(分离,把字符串按某个字符进行分割,返回分割后的值,返回值是一个切片)
strings.Split("a,b,c",",")
Trim(在s字符串的头部和尾部去除指定的字符串,最后三个感叹号都会去除,如果结尾没有感叹号就只去除开头的)
strings.Trim("!!!Anan!!!","!")
Fields(去除s字符串的空格符,并且按照空格分割返回一个切片类型,任意个空格都会去除)
strings.Fields(" a b c ")
|
字符串转换:(需要导入包strconv)
Append系列函数将整数等转换为字符串后,添加到现有的字节数组中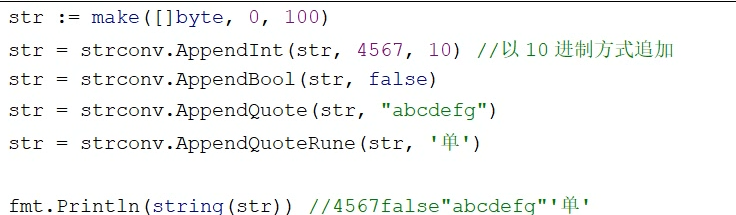
Parse系列函数把字符串转换为其他类型
Parse系列函数的返回值有两个,第一个是转换的值,第二个是error值,当转换失败时error会抛出错误,如转布尔值输入的是tr11ue
正则表达式的使用(导入包regexp)
1
2
3
4
5
6
7
|
buf := "abc adc aac a88 k8s"
//1.解释规则,它会解析正则表达式,如果成功返回解释器,失败返回nil
reg1 := regexp.MustCompile(`a.c`) //括号中可以用双引号和反引号,推荐反引号
//2.根据规则提取关键信息,-1表示匹配所有,1表示只匹配一个,返回的值是一个切片类型
result := reg1.FindAllStringSubmatch(buf, -1)
fmt.Println(result, result[2])
|
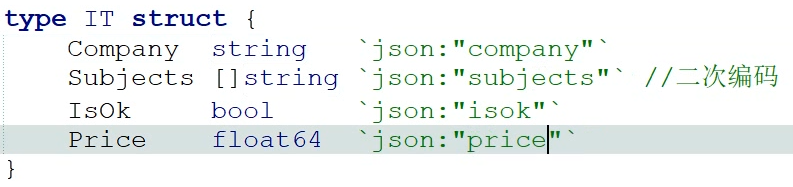
JSON处理(需要encoding/json包)
通过结构体生成json文件
默认情况下从结构体生成json格式,结构体的成员首字母必须大写,结构体名可以小写,因为在本包使用 Marshal方法是从本包传结构体到json的包让它编码,它肯定能访问到结构体,但是成员如果小写,json的包就无法调用到
1
2
3
4
5
6
7
8
9
10
11
12
13
|
type person struct {
Name string
Age int
}
func main() {
p1 := person{"张三",19}
b, _ := json.Marshal(p1)
fmt.Println(string(b))
var p2 person
json.Unmarshal(b, &p2) //结构体是值传递,如果不使用指针就只会修改副本,不会修改p2原有的内容
fmt.Println(p2)
}
|
Marshal()会返回两个值,一个json内容一个错误值,可以用If语句接受错误,然后用return让main函数中断,return在函数中的意义:如果函数返回值有定义,则return表示返回数据,如果没有定义返回值,return就表示退出此函数,在main函数中有return就表示中断程序但是不会报错
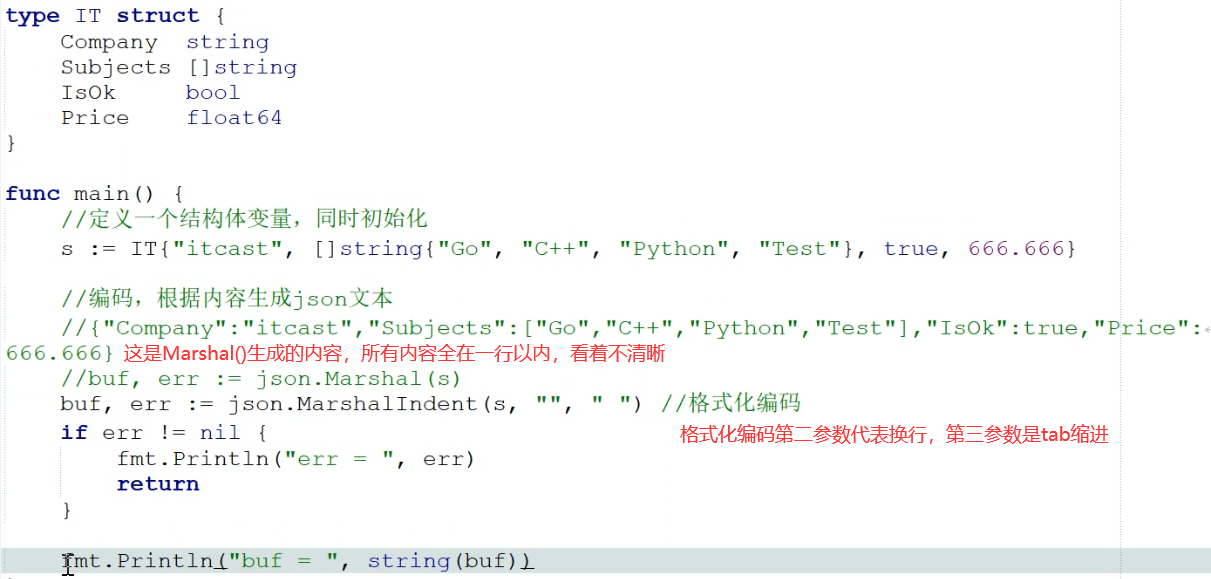
buf获得的值是一个字节切片类型,可以直接string(buf)强转成string类型
转换成string后输出的是一个整体值,无法再用切片[0]来调用任意一个成员
通过map生成json文件
MarshalIndent()的第三个参数为一个TAB键字符串
json解析到结构体(json解码)
json的变量名是小写,而结构体的首字母是大写,所以可以通过对结构体二次编码来关联上,不建议将结构体的首字母变成小写,因为如果变成小写的话,以后又需要生成json就会失败,并且如果程序其他地方有使用到这个结构体,成员名赋值也需要修改
Unmarshal()有两个参数,一个是byte切片类型(通过强转jsonBuf获得),一个是结构体的指针,放指针是因为给函数传结构体变量属于值传递,并不会修改本身结构体的内容,是拷贝了一份新的结构体给函数,只有通过指针实现引用传递才可以修改本身结构体内容,这个函数的返回值只有error
如果只需要部分解析,可以重新定义一个只含有部分成员的结构体来接受解析内容
json解析到map
map也需要传递指针过去,这里原理不太清楚,但是测试过发现不加指针&就无法对原值进行修改,尽管map属于引用传递
如果通过map接受解析的值,它接受到的值类型都属于空接口类型,对其强转string(m[“test”])是无法成功的,需要使用switch断言来回推类型进行赋值

switch可以在赋值的同时进行判断,即 switch a := 3; 判断的是st的值,空接口类型断言隐性的将data的类型放在了判断上面,且将data空接口类型自动转换成适合它的类型
推荐使用结构体来解析,因为map如果要确定值的类型就需要断言,过于麻烦
文件操作(需要os包)
设备文件有屏幕键盘等,标准输出就是屏幕,可以通过os.Stdout.Close()来阻止后面的程序输出内容,可以通过os.Stdint.Close()来阻止后面的程序通过键盘获取输入内容
文件的创建和写入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
path := "./test.txt"
//创建文件,如果文件存在则打开文件且清空文件内容,它返回一个file的指针和一个error
f, err := os.Create(path)
if err != nil {
//如果有错误就输出错误信息并且中止函数
fmt.Println(err)
return
}
//使用完毕记得要关闭文件,使用defer就可以在函数结束的前一刹那进行关闭
defer f.Close()
//Sprintln()可以将一行信息赋值给一个变量
buf := fmt.Sprintln("我往文件内写入东西")
//往文件内写入字符串,f代表文件的指针,WriteString就可以将内容追加到文件,注意是追加
//它返回两个值,一个是写入的字节数,另一个是error
n, err := f.WriteString(buf)
if err != nil {
fmt.Println(err)
return
}
|
文件的读取
下面的代码可以实现指定读取多少内容,如果想直接读完整个文件,只需要在读取那里加一个for循环,它就会一直往下读取直到结尾出现error抛出EOF错误(EOF表示结尾),注意:抛出EOF的if语句要写到err !=nil中,因为EOF错误是它的子集,在err不为空中加return,而EOF中只需要加break,因为break触发后直接跳出循环了,就不会触发return了
1
2
3
4
5
6
7
|
if err1 != nil {
if err1 == io.EOF{
break
}
fmt.Println(err1)
return
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
path := "./test.txt"
//打开文件,返回一个文件指针和一个error
f, err := os.Open(path)
if err != nil {
fmt.Println(err)
}
//函数运行结束时关闭文件
defer f.Close()
//创建一个2k长度的字节切片,表示读取的总量
buf := make([]byte, 1024*10)
//Read返回两个值,一个是字节数,一个是error
//n是读取了多少文件字节数,如果buf大于文件总字节数,n返回总字节数。
//如果总字节数大于buf,则n等于buf,即最多只能读取buf字节的内容,如果想多读取点就只能增大buf的长度值
//Read()方法会将读取的内容放入buf中,后面查看buf内容即是查看文件内容
n, err1 := f.Read(buf)
if err1 != nil && err1 != io.EOF { //文件出错并且没有读到结尾
fmt.Println(err1)
return
}
//可以用m:n来读取buf中间内容,n不能大于buf前面设定的值(即不能大于总长度),否则会报错
//n可以设置常量,即表示查看buf容量中从m到n的内容
//设置n则可以实现当文件总字节数小于buf量全部读取,大于则读取设置的最大值
fmt.Println("buf:", string(buf[:n]))
//buf中的值都是字节型的,可以通过强转变成string
|
如何一行一行的进行读取且务必读完文件的全部内容(不论大小)
bufio包有一个NewReader函数可以为文件的读取创建一个缓冲区并返回一个缓冲区的指针
ReadBytes是缓冲区 *Reader的方法,读取缓冲区直到第一次遇到delim字节(即指定的关键值’\n’等),读取出一次后缓冲区中对应的内容就会消失,因此可以用for死循环来读取多行缓冲区内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
path := "./test.txt"
//打开文件,返回一个文件指针和一个error
f, err := os.Open(path)
if err != nil {
fmt.Println(err)
}
//函数运行结束时关闭文件
defer f.Close()
//新建一个缓冲区,先把内容放进缓冲区里
r := bufio.NewReader(f)
for {
//遇到\n就结束读取,buf为读取到的数据,这种会将\n也读取进去,所以使用Printf()
buf, err1 := r.ReadBytes('\n')
//当读到结尾即退出循环
fmt.Printf("%v", string(buf))
/*把err判断放到打印后面的原因是如果将它放在前面,它会先判断是否是最后一行,当处于最后
一行时它直接跳出循环,最后一行的输出语句就不会进行,那么就会少输出一行
*/
if err1 != nil {
if err1 == io.EOF {
break
}
fmt.Println(err1)
}
}
|
实例:拷贝文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
//获取命令行参数,判断是否为3个
list := os.Args
if len(list) != 3 {
fmt.Println("拷贝格式为xx.exe src dst")
}
//比较目标文件和源文件是否同名
srcName := list[1]
dstName := list[2]
if srcName == dstName {
fmt.Println("源文件和目标文件不能相等")
}
//只读方式打开源文件
sf, err1 := os.Open(srcName)
if err1 != nil {
fmt.Println(err1)
return
}
//新建目标文件
df, err2 := os.Create(dstName)
if err2 != nil {
fmt.Println(err2)
return
}
//操作完毕要关闭文件
defer sf.Close()
defer df.Close()
for {
//读源文件
buf := make([]byte, 1024*4)
n, err3 := sf.Read(buf) //从源文件读取内容
if err3 != nil {
if err3 == io.EOF { //源文件读取完毕
break
}
fmt.Println(err3)
return
}
//写入目标文件,读多少写多少
_, err4 := df.Write(buf[:n])
if err4 != nil {
fmt.Println(err3)
return
}
}
|
go语言多线程
Go从语言层面就支持了并发,虽然并发程序的内存管理是非常复杂的,但是GO提供了自动垃圾回收机制
并行和并发的区别:并行指在同一时刻有多条指令在多个处理器上同时进行,并发指虽然在单个处理器上同一时刻只能有一条指令执行,但多个进程指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果
goroutine(协程)

通常main函数在一个单独的协程中运行,成为主协程,新的goroutine用go语句来创建,称为子协程,如果主协程中有for死循环,子协程要在死循环前建立,否则一直死循环就无法运行到创建子协程的语句
注意:主协程退出后,子协程会同时跟着退出
runtime包
Gosched()
Gosched()的作用就像linux中的进程优先级一样,但是如果在A协程中添加了runtime.Gosched()后,A协程会搁置到其他协程完成任务退出协程后再继续进行A协程
Goexit()
调用runtime.Goexit()将立即终止当前协程的进行,即使写在协程中的调用函数里也会中止当前协程
GOMAXPROCS()
调用runtime.GOMAXPROCS()用来设置 可以并发计算 的CPU核数的最大值,并返回之前的值
n := runtime.GOMAXPROCS(4) //以四核并发计算,核数可以大于当前系统的最大核数
channel类型
定义了两个函数person1和person2,虽然协程是同时进行的,但是两个公用了一个公共资源,最后打印就会出现这边打印一个字母那边打印一个,就造成了资源竞争问题。channel属于引用传递,即调用的都是同一个channel。
如果在person2中设置channel堵塞,它就会让此进程一直堵在channel步骤,而person1中先调用公共资源,person2暂停,当person1资源调用完毕后将int=666传入ch,子进程1结束,ch管道中有内容了不再堵塞,此时person2中的同一个ch管道将int传入函数并丢弃,然后继续执行后面的代码来调用公共资源,这样就可以避免资源竞争问题。
如果希望在子协程工作完成后再关闭主协程的话(主协程关闭会导致子协程同时关闭),可以在子协程中设置管道 ch<- “子协程完毕”,然后主协程接受这段内容并丢弃( <-ch ),这样就可以实现子协程没有进行到发送信息到管道那一步时,主协程ch永远堵塞,只有完成子协程任务并关闭后,主协程channel才有信息不堵塞,然后才可以正常完成主协程(channel也可以用于发送接受数据,类似linux的竖线管道)
无缓存通道和有缓存通道
channer分为无缓存通道和有缓存通道,无缓存channel没有接收或者没有发送都会造成堵塞,有缓存值的在写满缓存时就会造成堵塞,通道中没值时也无法取数据

有缓存cannel属于异步处理,每当接收者从cannel取出一条数据时,cannel中就会丢弃这条数据,将空间闲置出来给新的数据使用,当数据取完或写满时就会造成阻塞

close(ch)可以关闭通道,接收者可以通过 value,ok := <-ch来获取值,value为管道中的数据,ok在当管道没有关闭时为true,管道关闭了则为false
单项channel管道
双向channel可以隐式的转换为单向channel ( var writeCan chan<- int = ch ),单向无法转换为双向
案例:
channel可以通过range来依次读取通道内的数据,它的参数只有num,并非两个值。且必须搭配close(ch)使用,不然继续迭代下去,没有值但是还在进行<-ch,这会造成通道阻塞,出现死锁问题。在写入channel的函数中最后加上 close(ch) 就可以给它发送一个信号,它会在读取完全部值后退出for循环
由于channel属于引用传递,所以虽然函数的参数是单项通道,但是最终修改的依然是本来的双向通道ch,这可以避免在函数中又读又写造成逻辑混乱
定时器
Timer(类似一次性闹钟)
NewTimer只是返回了一个2s后的Timer指针变量,如果需要真的延时2s,必须使用 <-timer.C来将通道数据丢弃或赋值,因为它是在2s后接受数据并传入变量,在2s之前这个通道都是堵塞的(通道内没有数据),程序不会向下运行
NewTimer函数返回一个Timer的指针,Timer只会响应一次,过后不会再响应(一次性闹钟),即只会向cannel写一次2s后的时间
1
2
3
4
5
|
<-time.After(2 * time.Second) 定时程序2s,2s后产生一个事件,往channerl中写入时间(2s后那个时间点)数据
timer.Stop() 停止定时器
timer.Reset(1 * time.Second) 重新设置为1s
|
Ticker(类似循环闹钟)
Select (可以监听channel通道的数据流动)
注意:如果写了default,即每次都能判定成功,会导致select语句完成判定然后结束,不写就会(一直)阻塞直到case判定成功执行某一个case语句然后结束
如果select语句不加for循环,那么它只会判定一次并只将数据写入一次管道,监听一次就结束显然不符合监听的目的,所以需要往select外套一个for死循环来实现监听操作
第二个case语句,写入通道的操作必须要有一个读的操作(<-chan2)可以接收它的数据,只有写没有读是不能写成功的,有读没写也是不能读成功,都会造成管道死锁问题,这样就可以通过select实现在外部写入,select中的case读操作就判断成功。
注意:case不止是判断,它判断后面的语句能否读写成功,那么在判断成功的同时它也会往通道中读写数据
斐波那契数列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
func fibonacci(ch chan<- int, quit <-chan bool) {
x, y := 1, 1
for {
select {
case ch <- x:
x, y = y, x+y
case flag := <-quit:
return
}
}
}
func main() {
ch := make(chan int)
quit := make(chan bool)
//输出数字
go func() {
for i := 0; i < 8; i++ {
num := <-ch
fmt.Println(num)
}
quit <- true
}()
//产生数字,写入管道
fibonacci(ch, quit)
}
输出结果为:1 1 2 3 5 8 13 21
除去第二个数,其他数为前两个数相加
|
如果select语句不加for循环,那么它只会判定一次并只将数据写入一次管道,而fibonacci函数处于主协程,当判定成功后就会直接完成主协程,那么子协程也会退出,后面的数据都无法继续输出
用select实现超时退出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
ch := make(chan int)
quit := make(chan bool)
//监听管道数据
go func() {
for {
select {
case num := <-ch:
fmt.Println(num)
case <-time.NewTimer(3 * time.Second).C:
fmt.Println("3s没有输出数据")
quit <- true
return
}
}
}()
go func() {
for i := 0; i < 4; i++ {
ch <- i
time.Sleep(time.Second)
}
<-quit
fmt.Println("程序结束")
}()
for {}
|
当ch中没有数据时,case ch会堵塞,然后三秒后case time会有数据,执行case2,往quit管道中写入数据,最下面的读取quit就不会堵塞,程序就会继续执行,如果不希望主程序结束,可以将quit管道放到一个子协程中(且主程序有for循环之类的不会结束),那么三秒后子协程运行完自动退出,不会波及主协程
注意:case语句是会执行之后的语句的,所以time.NewTimer()会在3s后继续有值,且会再输出fmt,然后此时quit管道没接收者,会一直堵塞在这里,子协程会一直存在直到主协程关闭,所以加上return语句让它在第一次就关闭此函数,或者break跳出for循环
Socket网络编程(需要net包)
c/s架构
服务器部分:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
//设置监听,此处及下面都会返回err,为了缩短代码量丢弃了err,工作中不要丢弃
listener, _ := net.Listen("tcp", "127.0.0.1:8888")
//阻塞等待用户数据
conn, _ := listener.Accept()
//接收用户请求
buf := make([]byte, 1024)
//用户数据最后返回到了buf切片中,n表示从用户数据那读取的字节数,最大值为切片的长度1024
n, _ := conn.Read(buf)
fmt.Println(string(buf[:n]))
//最后处理完数据记得关闭连接
defer func() {
listener.Close()
conn.Close()
}()
|
服务器端先定义一个监听,表示将这个服务器以什么协议放置于什么位置,然后listener.Accept()让服务器阻塞等待用户向服务器端发送数据,用户发送数据后会存入conn中,通过conn.Read()来获取用户输入的数据并放到buf切片中,通过string(buf[:n])强转用户的字节数据为字符串,n表示数据量大于切片则返回切片最大值数据量,小于切片则返回全部数据,n返回的是Read所读取的总字节量,其值不会超过buf定义的1024字节
客户端部分:
1
2
3
4
5
|
//主动连接服务器
conn, _ := net.Dial("tcp", "127.0.0.1:8888")
//发送数据
conn.Write([]byte("are you ok?"))
defer conn.Close()
|
客户端部分只需要连接服务器并且发送数据,连接服务器需要指定服务器的ip端口和协议,发送的数据是字节切片类型
如何多个客户端同时连接同一个服务器(重要)
服务器端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
//conn的类型为net包里的Conn接口
func HandleConn(conn net.Conn) {
//每个用户使用完毕后关闭协程
defer conn.Close()
//获取客户端的网络信息,并以ip 端口的形式输出
addr := conn.RemoteAddr().String()
fmt.Println(addr, "---连接成功")
buf := make([]byte, 2048)
//用for循环套住Read(),用户发送一次数据,接收一次并赋值给buf,
//运行下面的打印和回传,再次循环并阻塞在Read()处等待用户再次发送请求
//但是这样会让子进程一直存在,除非设置了err不为空时退出实现强制退出
//因此加一个用户输入exit退出的逻辑
for{
n, _ := conn.Read(buf)
//打印用户发送过来的内容
fmt.Printf("%s输入了: %s\n", addr, string(buf[:n]))
//把用户信息转为大写发回给用户(先将小写的字节切片转为string,然后变成大写再强转为字节切片)
//n-是因为在windows中输入的语句有一个\r\n换行符,需要-2去除它
//各个平台都不一样,因此可以在前面通过len(string(buf[:n]))来判断到底多了几个字符
if string(buf[:n-2]) == "exit" {
fmt.Println(addr, " exit")
return
}
conn.Write([]byte(strings.ToUpper(string(buf[:n]))))
}
}
func main() {
//设置监听,此处及下面都会返回err,为了缩短代码量丢弃了err,工作中不要丢弃
listener, _ := net.Listen("tcp", "127.0.0.1:8888")
//利用for循环实现多个客户端连接同一个服务器
for {
//循环阻塞等待用户请求,一个用户请求然后往下走,然后循环继续等下一个用户
conn, _ := listener.Accept()
//开子协程处理多个用户请求,如果没有用户进入就会阻塞到第一步直到第一个用户请求,
//然后往下开一个新协程给此用户,继续for循环等待下一个用户请求
go HandleConn(conn)
}
defer listener.Close()
}
|
客户端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
func main() {
//主动连接服务端
conn, _ := net.Dial("tcp", "127.0.0.1:8888")
defer conn.Close()
//从键盘获取输入并发往服务器端
go func() {
str := make([]byte, 2048)
//用for循环可以实现当os.Stdin.Read()中没有数据时(即没有进行输入),
//阻塞在这一步,直到用户输入内容才继续向下进行
for {
//os.Stdin.Read可以提示键盘输入并且将输入的内容转换为字节切片,并赋值到str中,返回切片的长度
n, _ := os.Stdin.Read(str)
//发送给服务器端
conn.Write(str[:n])
}
}()
//从服务器端获取数据
buf := make([]byte, 2048)
for {
//for循环实现当服务器未往客户端发送数据时,conn.Read(buf)为空,阻塞在这一步,
//有数据循环一遍,然后等待下次服务器的数据
//当服务器端输入exit后,服务器端所对应的子协程结束,conn.Read()返回err,
//通过return结束主协程,子协程同时结束,退出程序
n, err := conn.Read(buf)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(buf[:n]))
}
}
|
远程发送文件:
服务器端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
func RecvFile(path string, conn net.Conn) {
//创建文件
f, _ := os.Create(path)
//循环接收文件的内容
buf := make([]byte, 1024*4)
for {
n, err := conn.Read(buf)
if err != nil {
if err == io.EOF {
fmt.Println("文件接收完毕")
} else {
fmt.Println(err)
}
return
}
//往文件写入内容
f.Write(buf[:n])
}
}
func main() {
//建立监听
listener, _ := net.Listen("tcp", "127.0.0.1:8888")
//阻塞等待用户请求
conn, _ := listener.Accept()
//接收用户文件名
buf := make([]byte, 1024)
n, _ := conn.Read(buf)
path := string(buf[:n])
//返回消息
conn.Write([]byte("开始发送"))
//接收文件内容
RecvFile(path, conn)
defer listener.Close()
defer conn.Close()
}
|
客户端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
func SendFile(path string, conn net.Conn) {
//打开文件,读取文件
f, _ := os.Open(path)
buf := make([]byte, 1024*4)
for {
n, err := f.Read(buf)
if err != nil {
if err == io.EOF {
fmt.Println("文件传输完成")
} else {
fmt.Println(err)
}
return
}
//发送到服务器
conn.Write(buf[:n])
}
defer f.Close()
defer conn.Close()
}
func main() {
fmt.Println("请输入文件名:")
var path string
fmt.Scan(&path)
//os.Stat()返回FileInfo类型变量,可以获取文件信息,info.Name()获取文件名,没有此文件则会报错
info, err := os.Stat(path)
if err != nil {
fmt.Println("没有这个文件", err)
return
}
//连接服务器,工作中err别丢空
conn, _ := net.Dial("tcp", "127.0.0.1:8888")
//给服务器先发送文件名,err和n都可以丢空
conn.Write([]byte(info.Name()))
//服务器接收到文件名,向客户端发送消息,客户端进行判断开始进行发送
buf := make([]byte, 1024)
n, _ := conn.Read(buf)
if string(buf[:n]) == "开始发送" {
SendFile(path, conn)
}
}
|
并发聊天服务器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
|
type Clinet struct {
C chan string //管道string类型,暂存用户发送的数据
Name string //用户名
Addr string //网络地址
}
var onlineMap = make(map[string]Clinet)
var message = make(chan string)
func WriteMsgToClient(cli Clinet, conn net.Conn) {
//这个是为了实现cli.C中有数据时向各自客户端发送数据,没有数据时阻塞在这一步
//且任意用户都会在登录时都会通过Manager()方法向每个用户的cli.C发送登录信息,
//只要cli.C一有信息,这个子协程就会检测到cli.C不再阻塞,就能向客户端写入新的他人登录信息
//只要发送处的管道没有关闭,cli.Close(),这个for就不会检测到false,会一直堵塞在这里
for msg := range cli.C {
conn.Write([]byte(msg + "\n"))
}
}
//将用户存进在线用户变量onlineMap中
func HandleConn(conn net.Conn) {
defer conn.Close()
//获取网络地址
cliAddr := conn.RemoteAddr().String()
//创建一个结构体,添加到map中
cli := Clinet{make(chan string), cliAddr, cliAddr}
onlineMap[cliAddr] = cli
//新开一个协程,专门给当前用户发送消息
go WriteMsgToClient(cli, conn)
//广播某个人在线
message <- "[" + cli.Name + "]---login"
//退出进行广播并且关闭子协程
isQuit := make(chan bool)
hasData := make(chan bool)
//新开一个协程,接收用户发送过来的请求
go func() {
buf := make([]byte, 2048)
//for循环可以避免输入一次就不再进行接收信息的问题
for {
n, _ := conn.Read(buf)
if n == 0 { //对方断开或者出问题
isQuit <- true
return
}
msg := string(buf[:n-2]) //过滤window末尾的/r/n符号
//查询所有用户
if len(msg) == 3 && msg == "who" { //避免whoami和who匹配
//遍历map,给当前用户发送所有成员
conn.Write([]byte("user list:\n"))
for _, tmp := range onlineMap {
msg = tmp.Name + "-----is online\n"
conn.Write([]byte(msg))
}
//给用户重命名,输入rename|mike
} else if len(msg) >= 8 && msg[:6] == "rename" {
name := strings.Split(msg, "|")[1] //将msg以|分割
cli.Name = name
conn.Write([]byte("u name is rename"))
} else {
//message复用来给所有用户广播它发送的消息,包括自己也看见
message <- cli.Name + ":" + msg
}
hasData <- true
}
}()
//用for循环让此子协程不会结束,避免发送消息后子协程结束,这个用户就通信结束了
//目的是让用户可以接收到后面登录和发送的信息,所以这个子协程就必须一直存在,除非用户退出
for {
//通过select检测管道isQuit的流动
select {
case <-isQuit:
//删除用户并且广播谁下线了
delete(onlineMap, cliAddr)
message <- cli.Name + "--is login out"
return
case <-hasData: //有数据不作处理
case <-time.After(60 * time.Second): //60s后超时执行此case,超时强制退出
delete(onlineMap, cliAddr)
message <- cli.Name + "--is time out leave out"
return
}
}
}
//新开一个协程,转发消息,只要消息来了就遍历map,给map每个成员都发送此消息
func Manager() {
for {
//mes为string类型的变量,自动推导类型
msg := <-message
//遍历map,给map每个成员都发送此消息
for _, cli := range onlineMap {
cli.C <- msg
}
}
}
func main() {
//监听
listener, _ := net.Listen("tcp", "127.0.0.1:8888")
defer listener.Close()
go Manager()
//循环
for {
//循环阻塞,形成多个客户端共用一个服务器
conn, _ := listener.Accept()
//处理用户连接
go HandleConn(conn)
}
}
|
先是主函数启动子协程HandleConn(conn),它作用于往map中写入在线成员,并将消息发给管道message,再通过Manager()将message管道发给msg字符串,遍历map,往每个map中的管道写入信息,紧接着通过WriteMsgToClient()中的range向客户端写入消息,且for遍历管道时,没有cli.Close()的存在,它会一直堵塞在此处等待新的信息写进cli.C
b/s架构:
但是如果工作中每次都需要向服务器发送一长串的请求包过于繁琐,所以可以使用net/http包来简化
http服务器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
//w为给客户端回复的数据
//req,读取客户端的数据
func HandConn(w http.ResponseWriter, req *http.Request) {
//给客户端浏览器发送数据
w.Write([]byte("hello go"))
//获取客户端的请求头部参数等
//在https://studygolang.com/pkgdoc中的net/http中搜type Request可以获取req的所有参数
fmt.Println(req.URL.Path)
}
func main() {
//注册处理函数,用户连接进来自动调用指定的处理函数(即如果域名后面接了/hello则调用后面那个函数)
//源代码中第二个参数为handler func(ResponseWriter, *Request)
//即在定义函数时已经定义了这是一个func,且默认已经传了两个参数进去,所以不需要加()来调用,
//自己写HandConn函数时也不再需要想办法获取ResponseWriter和*http.Request的值了
http.HandleFunc("/hello", HandConn)
//该方法用于在指定的网络地址进行监听,然后调用服务端处理程序来处理传入的连接请求
//该方法有两个参数:第一个为监听地址;第二个参数表示服务器端处理程序,通常为空
//第二个参数为空意味着服务端调用http.DefaultServerMux进行处理
http.ListenAndServe("127.0.0.1:8000", nil)
}
|
http客户端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
//获取从百度回传回来的请求包,http是必须要加的
resp, _ := http.Get("http://www.baidu.com")
//body是从服务器端读取资源(类似于conn.Read()),最后是需要进行关闭的
defer resp.Body.Close()
fmt.Println("Status =", resp.Status)
fmt.Println("StatusCode =", resp.StatusCode)
fmt.Println("Header =", resp.Header)
//获取baidu.com中的数据Read(),然后赋值给buf,最后追加到tmp中
buf := make([]byte, 1024*4)
var tmp string
for {
n, err := resp.Body.Read(buf)
if n == 0 {
fmt.Println("read err =", err)
break
}
tmp += string(buf[:n])
}
fmt.Println(tmp)
|
用go写爬虫爬百度贴吧:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
func SpiderPage(i int, page chan int) {
//寻找网址规律,每页pn加50,用for循环获取每个网址
url := "http://tieba.baidu.com/f?kw=%E6%8A%97%E5%8E%8B%E8%83%8C%E9%94%85&ie=utf-8&pn=" + strconv.Itoa((i-1)*50)
fmt.Printf("正在爬取第%d页网页%s\n", i, url)
result, _ := HttpGet(url)
//将内容写到文件中
f, _ := os.Create(strconv.Itoa(i) + ".html")
f.Write([]byte(result))
f.Close()
page <- i
}
func HttpGet(url string) (result string, err error) {
rep, _ := http.Get(url)
defer rep.Body.Close()
//爬取
buf := make([]byte, 1024*4)
for {
n, err := rep.Body.Read(buf)
if n == 0 {
fmt.Println(err)
break
}
result += string(buf[:n])
}
return
}
func DoWork(start, end int) {
fmt.Printf("正在爬取 %d到%d的页面。。。", start, end)
//建立一个管道,避免主进程结束导致子进程结束
page := make(chan int)
//获取地址
for i := start; i <= end; i++ {
//建立子协程,让多个爬虫同时进行
go SpiderPage(i, page)
}
for i := start; i <= end; i++ {
//避免协程结束影响子协程
fmt.Printf("第%d页已经读取完毕", <-page)
}
return
}
func main() {
var start, end int
fmt.Println("请输入起始页")
fmt.Scan(&start)
fmt.Println("请输入结束页")
fmt.Scan(&end)
DoWork(start, end)
}
|
此方法可以爬取每页内容(包括html内容)存到新建的.html中,如果要爬取需要的内容,可以查看源代码然后通过正则表达式爬出来再存入文件中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
如爬取每个帖子的某段内容,先在每个主页查看源代码爬取出每个帖子的url,
<a rel="noreferrer" href="/p/6978750013" title="老马是真的叼,剪辑的更吊!!!" target="_blank" class="j_th_tit "
用正则表达式 (`<a rel="noreferrer" href="(?s:(.*?))" title=`) 来爬取出网页链接,
regexp的FindAllStringSubmatch会返回一个二维切片,切片中的里切片第一个值是通过表达式过滤出的内容,
第二个值是正则表达式代表的内容,即/p/6978750013,给它拼接上贴吧网址即可访问
通过range迭代外切片然后在里面调用里切片[1]即可
然后在range中用http.Get爬取内容,依然是查看源代码找到对应的内容进行过滤
过来出来的内容可能会有些\t <br />之类的,可以用strings.Replace(text,"\t","",-1)去掉
最后写入文件,如果多标题多内容,可以分开存入到两个切片中,然后后面一口气写进文件中
|
如果不用子协程来爬取,它就是单协程的程序,它会爬完一个再爬下一个,开了子协程后它可以同时爬取多个,节省了大量时间,但是要注意子协程开启后主协程不能关闭,这样会导致子协程也同时消失,可以使用切片来阻塞主协程,直到爬取完毕
常见知识点
- switch中隐式含有break,但是select中必须要用break或continue跳出循环
- 结构体实现接口时不需要导入接口所在的包
- 一个go文件中可以包含多个init同名函数,他属于官方在内存中定义的函数,自上而下运行,自己定义的函数不能同名
- 变量定义可以用中文,会转换成ASCII码,变量名中不能有$
- string不能用nil,它的空值为“”空字符串
- make([]int,0)初始化切片的时候,必须要指定容量,即使是0,不指定会报错
- golang的自增自减++ – 只有后置,没有前置
- 只要两个接口拥有相同的方法列表,那么它们就是等价的,可以相互赋值。
- cap函数(容量大小)只能传数组,切片,管道
- recover()在func()外运行是无法阻止异常的,必须要写func(){recover()}才能处理异常
- 指针、数组、切片、map字典、结构体都属于复合类型
- new()返回*T,只分配内存,不初始化。make返回T,分配并初始化,只适用于map,slice,chan