适用于mongodb的业务场景:
- 数据量大
- 写入操作频繁(读写都很频繁)
- 价值较低的数据,对事物要求不高(mongodb对于事物的支持不是很好)
什么时候选择mongodb:
- 应用不需要事物及复杂的join支持
- 新应用,需求会变,数据模型无法确定,想快速迭代开发
- 应用需要高读写速率,需要2000-3000以上的读写QPS
- 应用需要TB及PB级别的数据存储(维护成本较mysql低)
- 应用要求存储的数据不丢失
- 应用需要99.9999…%高可用
- 应用需要大量的地理位置查询、文本查询
如果上述有一个符合就可以考虑使用mongodb,2个以上直接选择使用mongodb就行

基础mongodb命令
|
|
|
|
配置文件内容:

|
|
CRUD
数据库操作
在每个集合中都会存在一个 _id,这个是mongdb的主键,它自己生成的
显示数据库
|
|
选择和创建数据库
|
|
如果库不存在则自动创建,有则切换到此库
要注意的是,在mongodb中,要新建了一个集合后才会真正的创建一个库。
原因是use后这个库会先存在于内存中,只有当往这个库中写入了数据,mongodb才会持久化这个库到磁盘中。
删除数据库
|
|
默认库的作用
- admin: 从权限的角度来看,这就类似于mysql的root数据库,如果将一个用户添加到这个数据库中,这个用户就自动继承所有数据库的权限。一些特定的服务器命令也只能在这个数据库中运行,比如关闭服务器。
- local: 这个数据库中的数据永远不会被复制,作用于集群,集群之间是会相互复制彼此的数据,当数据存于这个库中时,数据就不会被集群中的其他库所复制,可以用来存储限于本地单台服务器的任意集合。
- config: 当mongodb用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
集合操作
集合类似于关系型数据库中的表。它可以显式创建也可以隐式创建。
|
|
|
|
当向一个集合中插入一个文档的时候,如果集合不存在,则会自动创建集合。通常使用隐式创建即可
|
|
文档基本CRUD
文档的数据结构和JSON基本一样,所有存储在集合中的数据都是BSON格式。
单个文档的插入
使用insert()或save()方法向集合中插入文档,语法如下:
|
|

|
|
要注意的是:当插入多条时如果某条数据插入失败,将会终止插入,但已经插入成功的数据不会回滚掉。
因此批量插入时最好可以加上try-catch来进行异常捕捉处理
|
|
文档的查询
基本查询
|
|
此时会发现在文档中会有一个叫_id的字段,这个相当于MySQL的主键ID,在插入文档时没有指定该字段则MongoDB会自动创建,其类型是ObjectID类型。当然在插入文档时也可以指定_id为自己设置的值,建议不要自己指定_id,因为重复后会很麻烦。
|
|
|
|

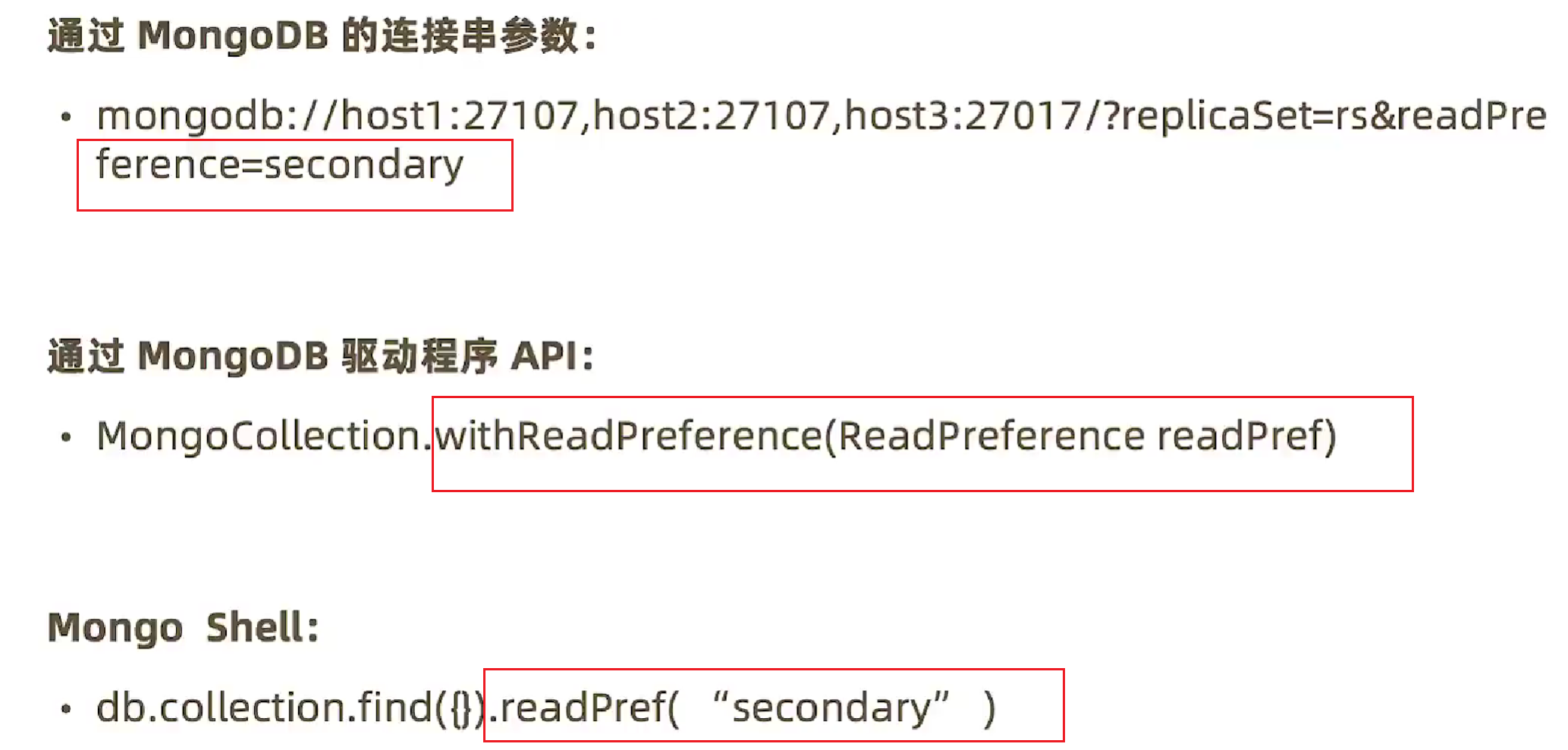
投影查询
相当于mysql的select id,name from user,即只显示指定的字段,其中value为1则表示显示此key字段,为0则为不显示,_id默认是显示的,所以必须设置为0让其不显示,其他字段只要没有显式设置,默认都是不显示
|
|
聚合查询
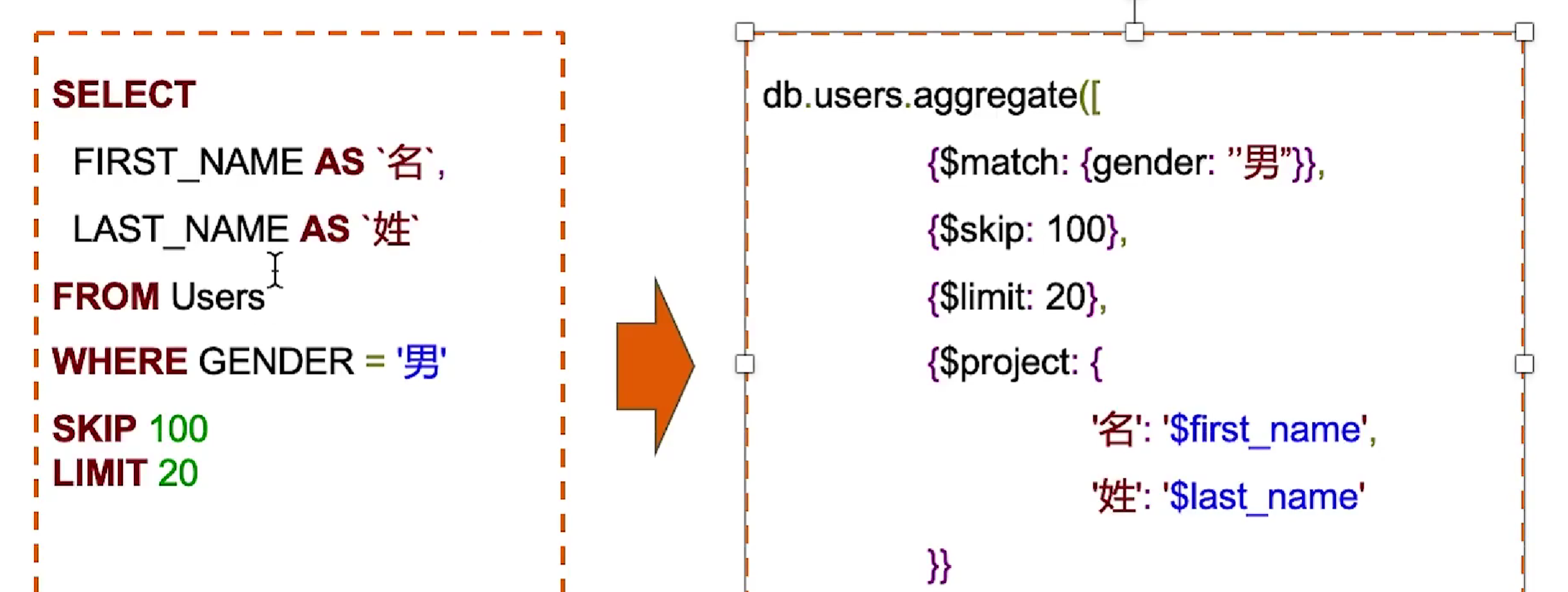

示例
lookup只支持left outer join
文档的更新
|
|
覆盖修改
|
|
update字段的age可以为文档中不存在的值,此时这个文档除了age和_id,其他字段都不见了,此为覆盖修改
局部修改
|
|
只修改指定的字段,其他字段不变
批量修改
覆盖修改和局部修改都只会修改一个文档,必须使用批量修改来改集合中满足条件的所有文档
|
|
列值增长的修改
如果想对某列值在原有的基础上进行增加和减少,可以使用 $inc 运算符来实现。
|
|
文档的删除
|
|
|
|
文档的分页查询
统计查询
|
|
分页列表查询
可以使用limit()方法来读取指定数量的数据,使用skip()方法来跳过指定数量的数据。limit默认是20,skip默认是0
|
|
排序查询
sort()方法可以通过参数指定排序的字段来对数据进行排序,并用 1和-1来指定排序的方式,其中1为升序排列,-1为降序排列。
|
|
注意:
skip(),limit(),sort()三个放一起执行的时候,执行顺序是sort(),skip(),limit(),和命令的编写顺序无关。
复杂查询
正则的复杂条件查询
mongodb的模糊查询是通过正则表达式的方式实现的。其正则是用js的写法
|
|
name后的value不要加引号,这表示此为字符串,变成等于了
比较查询
包含查询
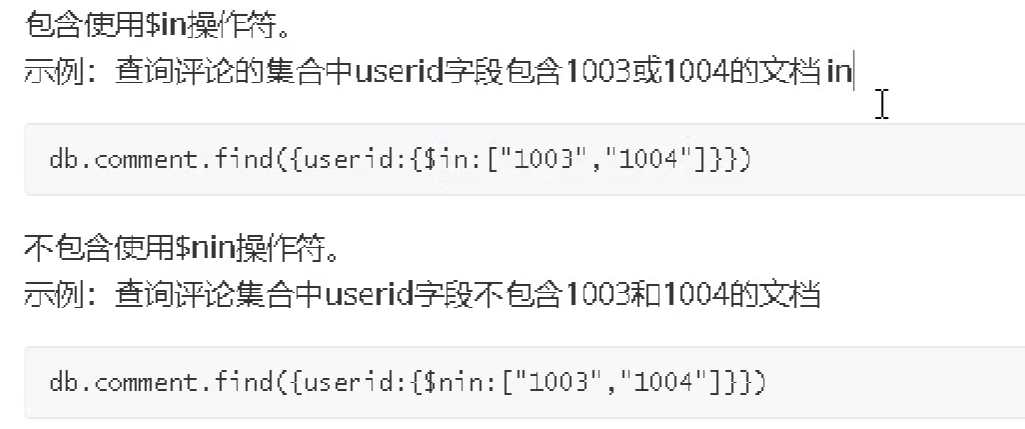
条件连接查询
索引
索引支持在mongodb中高效的执行查询。如果没有索引,mongodb必须执行全集合扫描,即扫描集合中的每个文档来选择与查询语句匹配的文档。这种扫描全集合的查询效率是非常低的,尤其是在处理大量数据时,查询可能要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
如果查询存在适当的索引,mongodb可以使用该索引限制必须检查的文档数。
索引是特殊的数据结构,它以易于遍历的形式存储集合数据集的一小部分。索引存储特定字段或一组字段的值,按字段值排序。索引项的排序支持有效的相等匹配和基于范围的查询操作。还可以使用索引中的排序返回排序结果。
mongodb索引使用的是B tree 数据结构,MySQL是B+ tree
多路动态平衡树,简称b-tree,效率高,尤其是可以最大提高磁盘io效率,所以大部分数据库的存储引擎都用b-tree或者b-tree增强版作为索引的数据存储结构
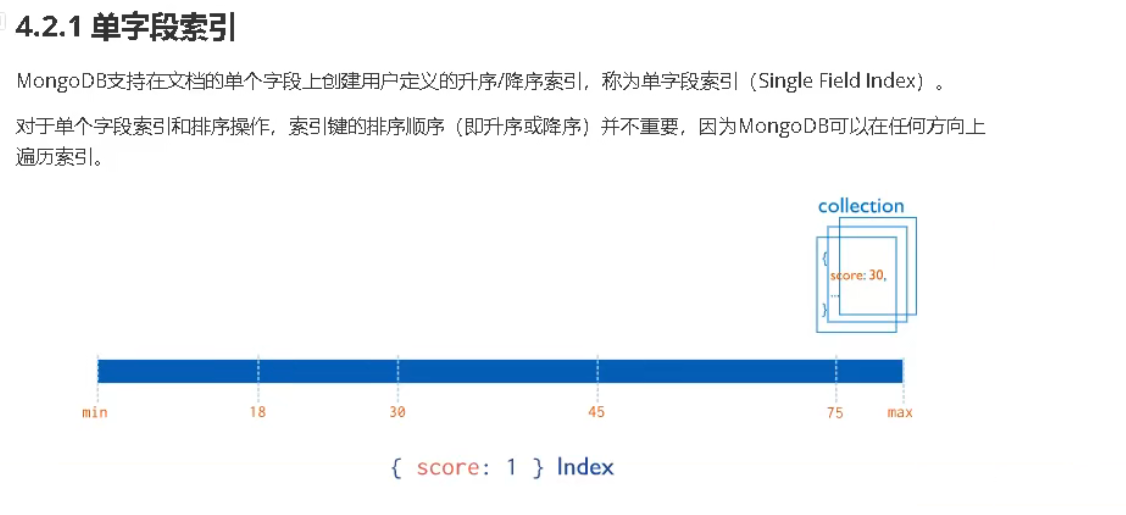
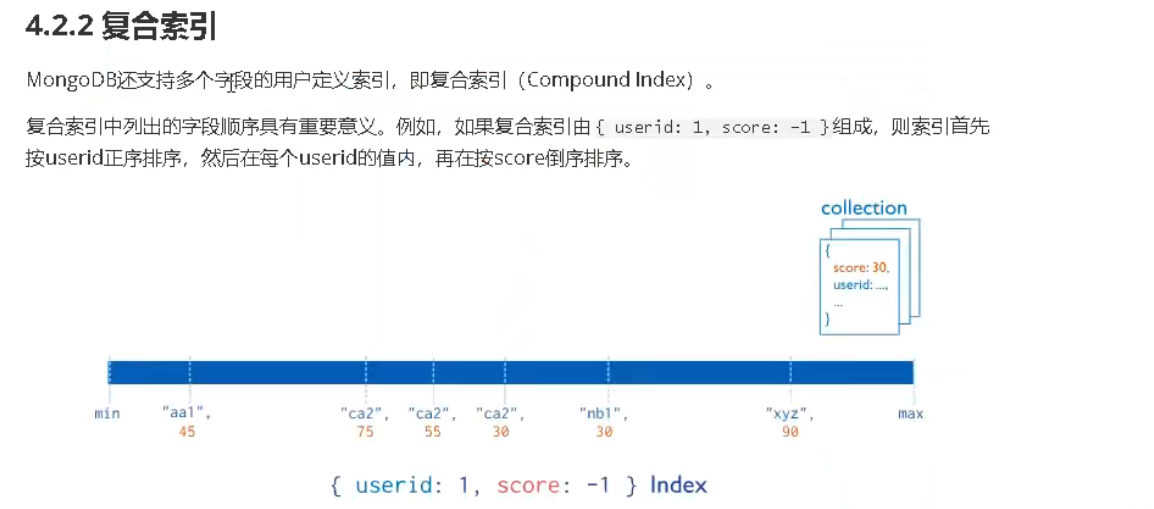
索引的查看
返回一个集合中的所有索引的数组。
|
|
索引的创建
|
|
索引的移除
|
|
|
|
执行计划
|
|
分析查询语句,查看是否用上了索引
设计模式
分桶设计
每分钟写入一次,如果运行一年则数据量极大,采用分桶模式进行分组,因为展现数据一般不会基于一分钟进行展现,最低级别可能都是一小时,因此将其合为一组即可极大的优化数据容量和读取速度。一般适用于数据点采集频繁,数据量过多的场景中。

列转行
导致创建新数据时要花费更多的数据,则可以采用列转行的方式,将相似的列变成一个列
版本字段

近似计算
在所需要的计算非常有挑战性或消耗的资源昂贵(时间、内存、CPU周期)时,如果精度不是首要考虑因素时,那么我们就可以使用近似值模式。
假设现在有一个相当规模的城市,大约有3.9万人。人口的确切数字是相当不稳定的,人们会搬入搬出、有婴儿会出生、有人会死亡。我们也许要花上整天的时间来得到每天确切的居民数量。在应用程序中,我们不需要每次更改都去更新数据库中的人口数。我们可以构建一个计数器,只在每达到100的时候才去更新数据库,这样只用原来1%的时间。在这个例子里,我们的写操作显著减少了99%。还有一种做法是创建一个返回随机数的函数。比如该函数返回一个0到100之间的数字,它在大约1%的时间会返回0。当这个条件满足时,我们就把计数器增加100。
我们为什么需要关心这个?当数据量很大或用户量很多时,对写操作性能的影响也会变得很明显。规模越大,影响也越大,而当数据有一定规模时,这通常是你最需要关心的。通过减少写操作以及不必要的“完美”,可以极大地提高性能。
预聚合字段
因为计算需要一行一行的扫描进行计算,因此可以采用预聚合模式

mongodb事物
写事物
|
|
读事物
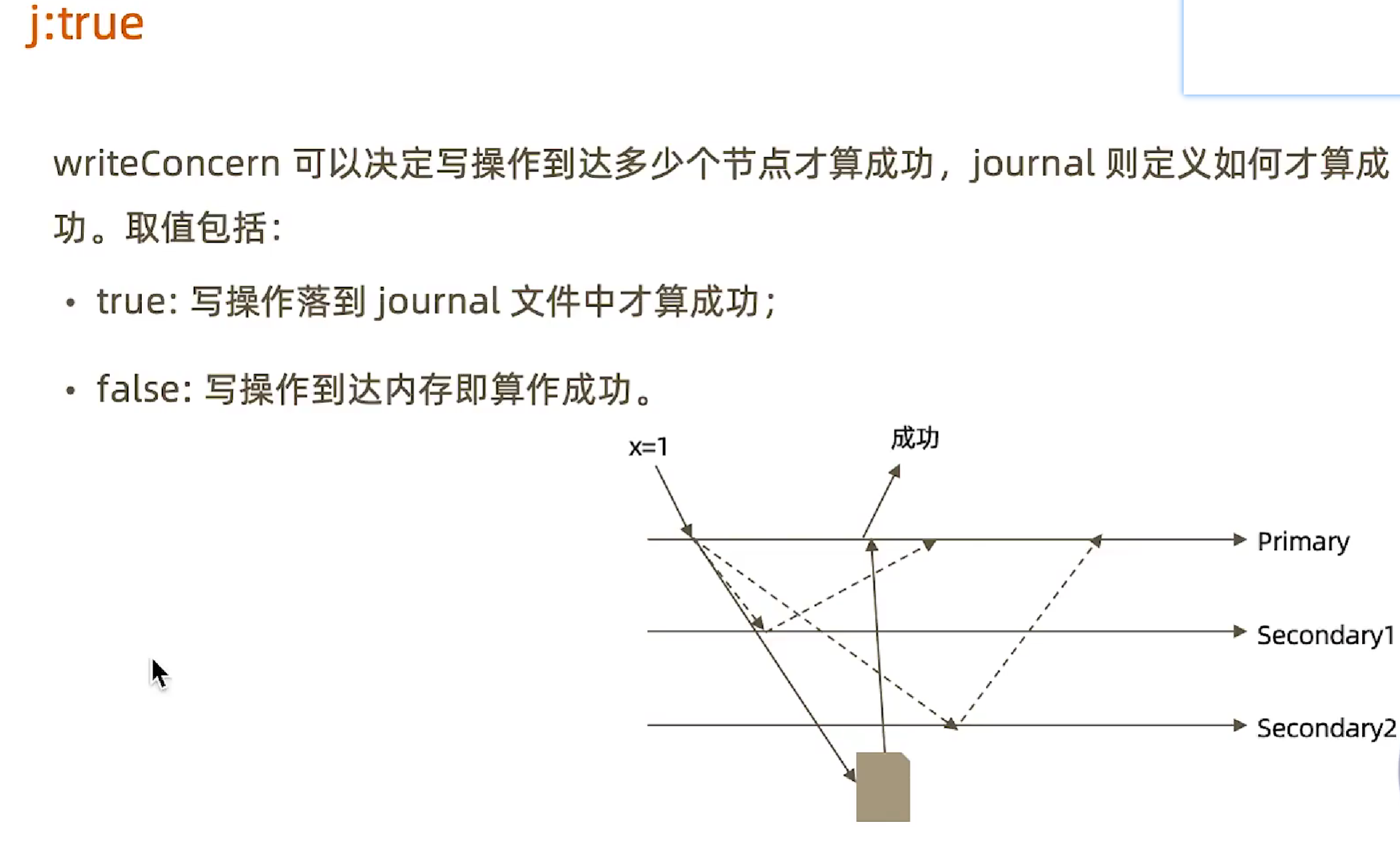
readPreference (选择读哪个节点的数据)
默认是primary,并且这是推荐的做法,因为这样读肯定是读到最新的数据。nearest是根据ping time来决定。
readConcern (隔离级别)


|
|
如果要使用majority级别必须要在配置文件中配置enableMajorityReadConcern=true (记住所有写操作的位置和状态)

多文档事物 (重要,平常代码中使用的事物)


Change Stream (触发器)

mongodb 代码编写规范