Redis,远程字典服务,是由C语言开发的一个开源的高性能键值对数据库。
set key value 添加修改数据,get/del key 获取删除数据。操作时返回 (integer) 1 则是操作成功,0则是失败
redis为每个独立的redis服务提供了16个数据库,编号从0到15。每个数据库之间的数据相互独立,且数据库大小是动态扩容。通过 select [0-15] 来切换到其他数据库中。默认是在0号数据库。
move key db 将当前库的某个key移动到其他库中,当前库必须要有这个key且对方库必须不能存在这个key,两者任意一个条件不满足都会移动失败。
dbsize 可以查看当前库存在多少个key。flushdb 清空当前库的key flushall 清空所有key
数据类型
string




在setex之后再使用setex会刷新时效性为新设置的秒数值

hash

hsetnx key field value 设置field的值,如果原本存在则不设置,不存在才进行set
list
stop为-1就表示最后一个数据,lindex表示查看某个索引的值,查最后一个也可以使用-1
读取只有lrange,这说明读索引依然是从左往右读取,因此如果是lpush那它是从最后一个往前插入数据;rpush则是从第一个开始往后添加数据
lpop表示移出list中左边的一个值,rpop则是右边出一个。根据索引都是从第一条往后读,lpop是从第一个开始往下进行移出,rpop是从最后一个往前移出

并且它可以同时等待多个list,某个list有就取,全没有才进行等待。
lrem key count value 移除指定数据,count表示移除几个,因为值等于value的可能会有多个
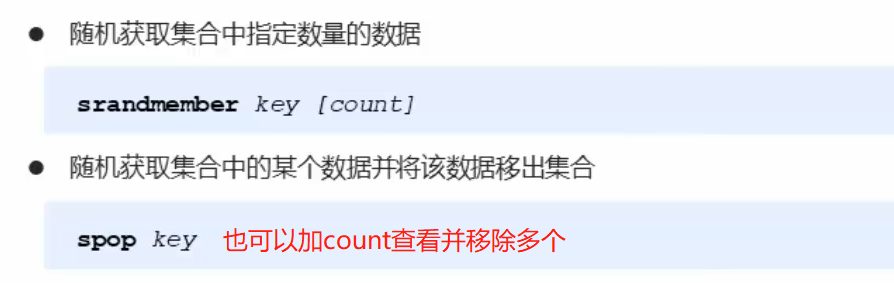
set
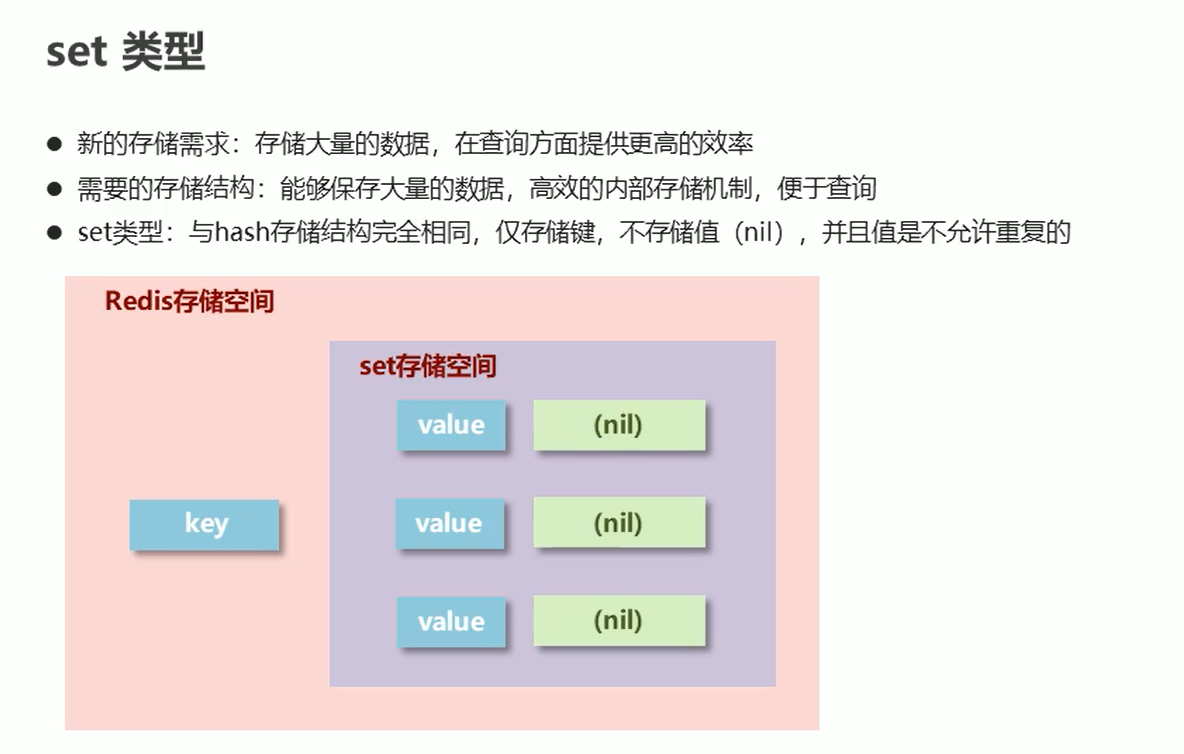
set类型不允许值数据重复,如果添加的数据在set中已经存在一份,则会添加失败。[因为添加相同的数据是没有意义的]。可以根据这个去重特性做权限控制或者网站访问统计

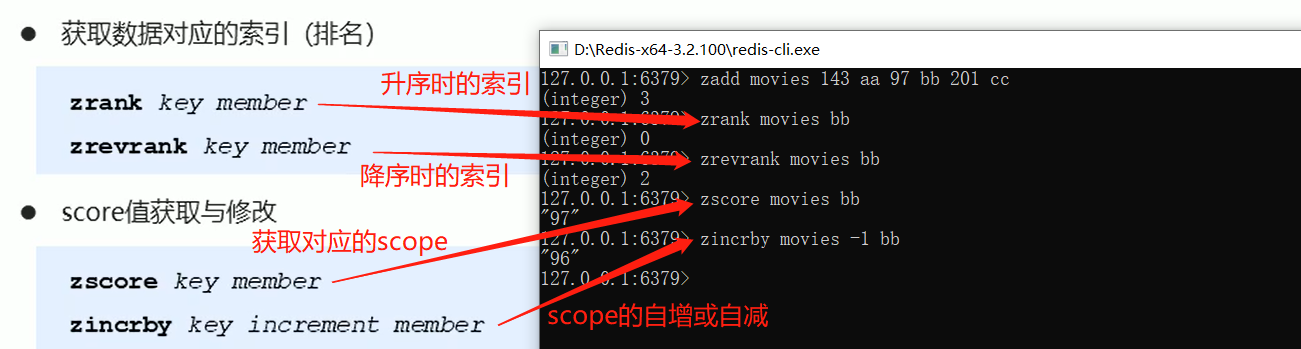
sorted_set
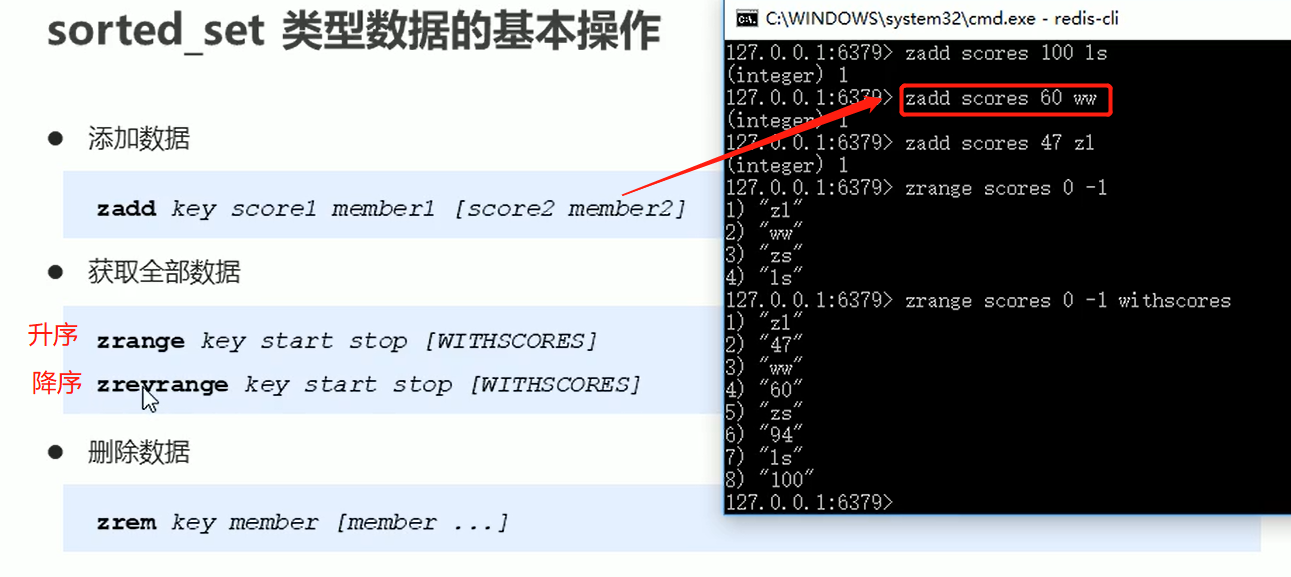
zremrangebyrank是根据索引删除,且索引来自于zrange显示的顺序。
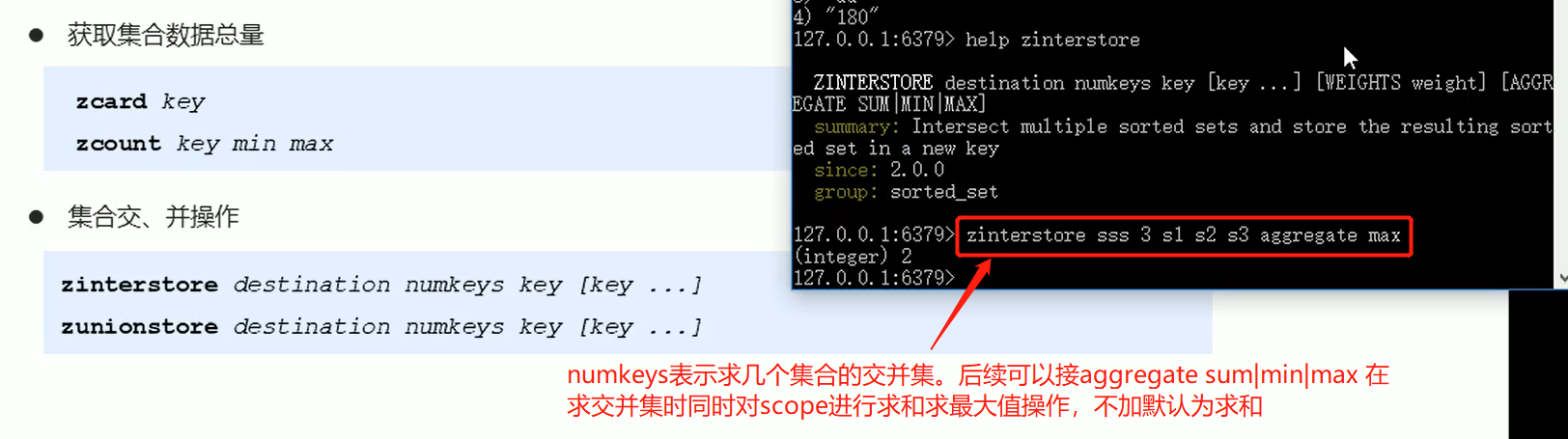
sorted_set底层存储依然是基于set结构的,因此数据不能重复,重复添加一个相同的数据,它的值会添加失败,但是如果新增时附带的score值不同,它的score值将被反复覆盖,保留最后一次修改的结果。
key通用操作
Linux安装redis
下载安装一条龙
|
|
服务器的redis通常会启动多个,因此启动根据配置文件进行启动
|
|

持久化(优先使用AOF)

官方推荐两个方法同时使用
RDB

如果出现意外情况导致redis崩溃消失,在下次启动时,redis会自动加载这个dump.rdb文件进行数据恢复,不需要人为操作恢复
要注意的是 save指令的执行会阻塞当前redis服务器(执行完才能进行后续的set等命令),直到当前rdb过程完成为止,有可能造成长时间阻塞,线上环境不建议使用。
可以使用bgsave来替代save,它会生成一个Linux子进程,而不占用redis的进程
bgsave命令是针对save阻塞问题做的优化。redis内部所有涉及到reb操作都建议采用bgsave的方式。save命令可以放弃使用了
但是不能说每次程序调用set方法就由程序发送bgsave方法,可以设置自动执行来让服务器自己进行保存
发生变化包括修改原有key的value,新增key,删除key
AOF
最后根据策略将AOF缓存的写记录数据存放到 .aof文件中
**bgrewriteaof 手动后台重写,逻辑和bgsave相似。**要注意的是对一个数据修改删除之后,重写完这个数据的操作会消失,因为它在redis中已经被删除了
在这两种重写条件中选择一种即可,而size的单位是字节,即linux输入ls -l显示的大小值
事务
事务的工作流程
锁
watch锁(乐观锁,通过监听一个字段是否改变来确定后面的事务是否失败)
终止执行是直接discard。之前的执行语句都得重写进行
watch和mysql的锁有点区别,watch定义在开启事务之前,且watch key和事务中的字段没关系。比如对name进行watch,然后开启事务后set的是 age,假如在没有执行exec前另一个服务器对name字段的值进行了改变,它是可以成功改变name的值的。而此时执行exec就会失败,不存在阻塞的情况。
只有当watch的对象没有改变时,后面的事务才能成功执行。watch的key改变与否影响着下一个事务的执行,但key的值和事务中的操作值没有关系。watch定义在事务开始之前,和mysql完全不相同
setnx 锁(悲观锁,通过设置一个锁来确定之后代码是否执行)
它依然不会阻塞,且value值可以任意,假如在会话1中 setnx lock-age 1 ,此时会话1可以 set age 3 ,但会话2也可以 set age 3 ,**这个锁不会对age字段进行加锁。**它只会对 lock-age 加锁,如果会话2再加一次 set lock-age 1 就会发生失败,因为程序中每次都要使用一次lock-age ,如果失败则意味着有其他地方加锁了。解锁则是删除这个锁,del lock-age
但是经常会出现加锁却忘记解锁的情况,就需要使用 expire lock-key second 来给锁加个生存周期。这个指令只能添加生存周期,因此加生存周期之前要使用setnx进行加锁
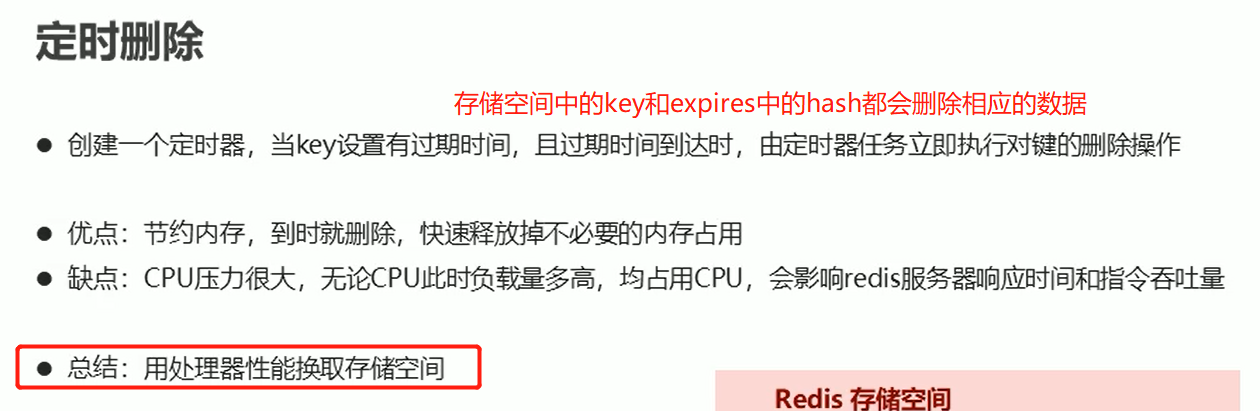
删除策略
过期数据
过期数据一般不会立即删除,它会根据删除策略来延迟删除。过期数据的底层就是开辟了一个空间来存key的内存指针和过期时间,如果到了这个时间点才根据策略进行删除。而开辟的这个空间的结构是hash类型,一个failed一个value,failed存key的内存指针,value存它的过期时间
redis会在内存占用和CPU占用之间寻找一个平衡,顾此失彼都会造成整体redis性能的下降,甚至引发服务器宕机或内存泄漏
删除策略
拿时间换空间
拿空间换时间(图片写错了)
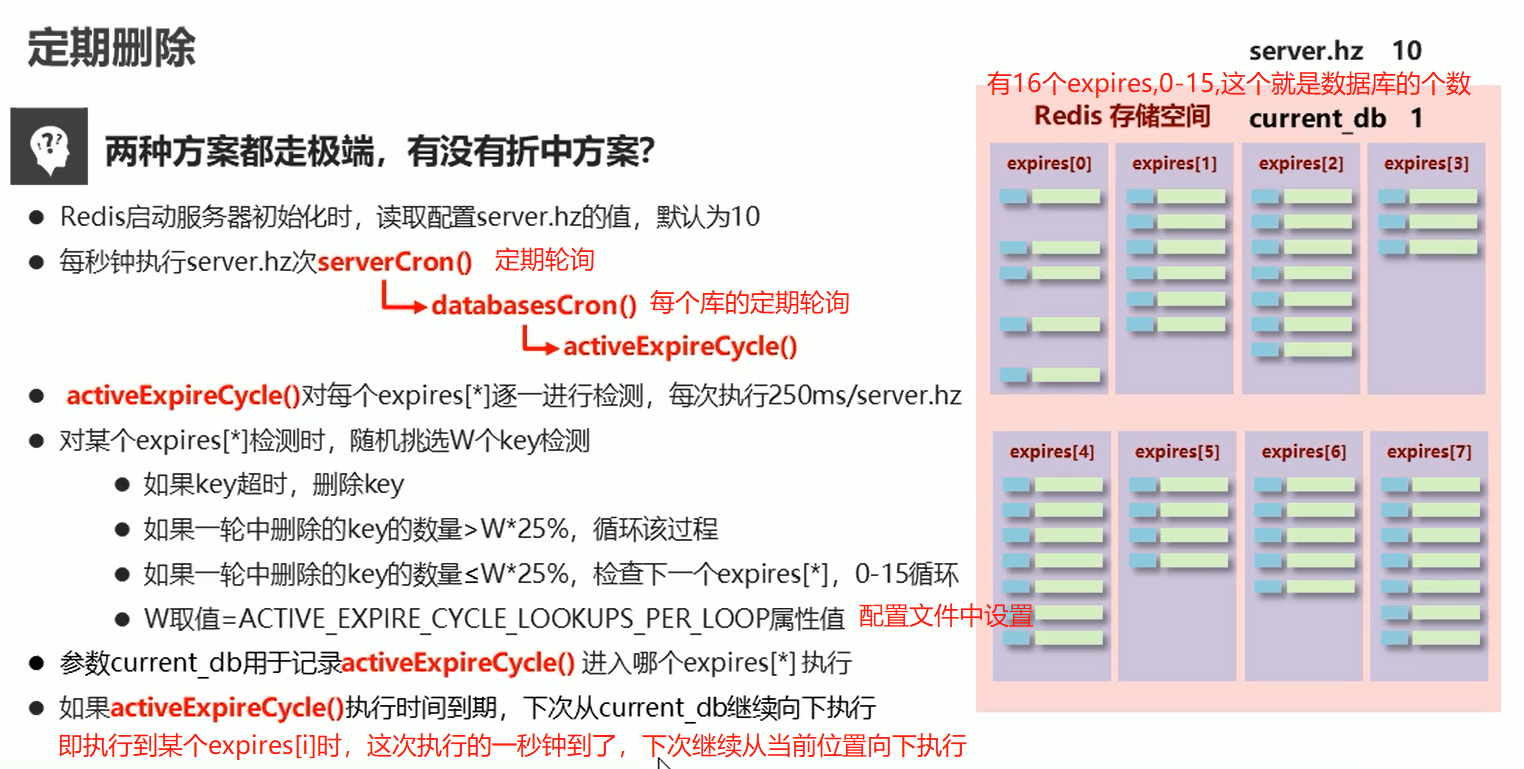
折中方案,server.hz通过info server 查看hz
逐出算法
前四个是操作过期数据,后三个操作全部数据,最后一个都不处理
redis.conf配置部分介绍

高级数据类型
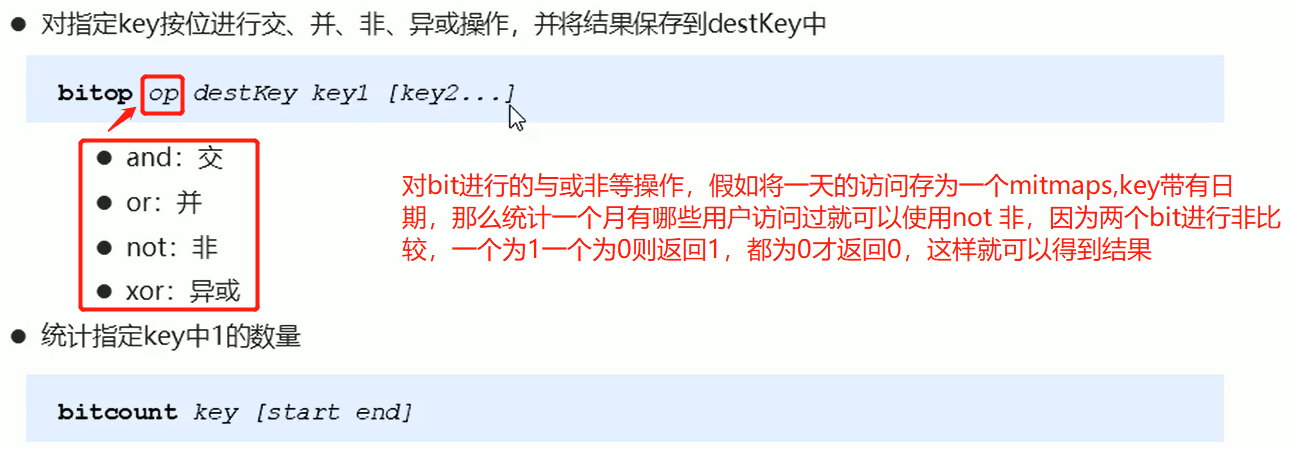
Bitmaps(针对状态统计)
Bitmaps本身不是一种数据结构, 实际上它就是字符串,但是它可以对字符串的位进行操作**。Bitmaps并不是实际的数据类型,而是定义在String类型上的一个面向字节操作的集合。** Bitmaps单独提供了一套命令, 所以在Redis中使用Bitmaps和使用字符串的方法不太相同。可以把Bitmaps想象成一个以位为单位的数组, 数组的每个单元只能存储0和1, 数组的下标在Bitmaps中叫做偏移量。
bitmaps通常作用在统计用户访问量,因为一个用户只有访问和未访问两种状态,为此存储用户的uid会极大的浪费redis的内存。那么以1表示访问,以0表示未访问,而bitmaps的下标索引则代表这个用户的uid,则可以缩减所需内存。
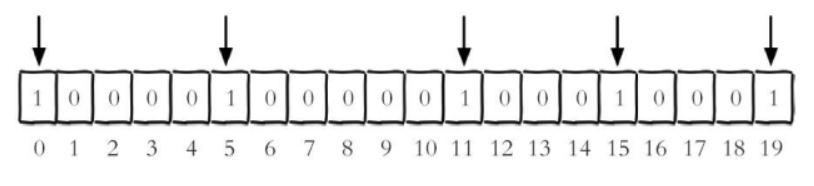
假设现在有20个用户,userid=0, 5, 11, 15, 19的用户对网站进行了访问, 那么当前Bitmaps初始化结果如下图所示。
那么设置id为5的bit为1则是 setbit testkey 4 1 设置索引为4的bit为1,取则是 getbit testkey 4,返回的0和1则是代表是否被点播,而4之前的值都会被0填充。而取不存在的位,如 getbit testkey 10 也是能取到的,它被填充为了0
很多应用的用户id以一个指定数字(例如10000) 开头, 直接将用户id和Bitmaps的偏移量对应势必会造成一定的浪费, 通常的做法是每次做setbit操作时将用户id减去这个指定数字(之前的10000)。 在第一次初始化Bitmaps时, 假如偏移量非常大, 那么整个初始化过程执行会比较慢, 可能会造成Redis的阻塞
bitpos key targetBit 返回第一个值为targetBit(0/1)的偏移量
HyperLogLog (基数统计,专用于统计不重复的数据的数量)
GEO (地理定位计算,只能计算水平位置的距离)

主从复制(读写分离)

只需要在从机使用slaveof 主机ip 主机port 就可以开始连接了,然后看下主机和从机是否有同步数据成功的日志即可。同步成功后从机只能进行get读的操作,写会失败,且每次主机set一次,从机就可以get到最新的数据
也可以在启动从机时 在redis-cli后加 –slaveof 127.0.0.1 6379
但是最常用的还是修改配置文件的方法: 在从机的redis.conf中加 slaveof 主机ip 主机port
slaveof no one 从机发送命令,断开主从连接
全量复制指的是从发psync2指令那一刻开始主机原来的所有数据,而部分数据则是进行rdb过程中所有的数据,后面发送的指令已经属于命令传播阶段了
命令传播阶段会因为短时间的网络中断 开启 部分复制
如slave重连master时,如果运行id和上次不同,就需要判断是否是同一台机器,如果不是就得进行全量复制了。运行id主要用于识别对方身份
数据同步阶段:
蓝色的runid和offset是全量复制时主发给从的 主机runid和offset,红色也是主机的runid和offset[当前的偏移量]。offset如果不在缓冲区就说明被挤出去了,就得重新全量复制
命令传播阶段:
master的复制缓冲区会暂存传播的命令和偏移量。如果从机发来的偏移量和主机记录的偏移量不同则可以知道主机更新了哪些数据[即使两者连接断开],如果从机发来的偏移量不在主机的复制缓冲区中,则意味着数据过早,已经被挤出缓存区了,只能重新进行全量复制。
lag项大于1就说明曾经slave掉过
常见问题:
哨兵
配置文件
启动顺序为先启动主节点,再从节点,然后再启动哨兵
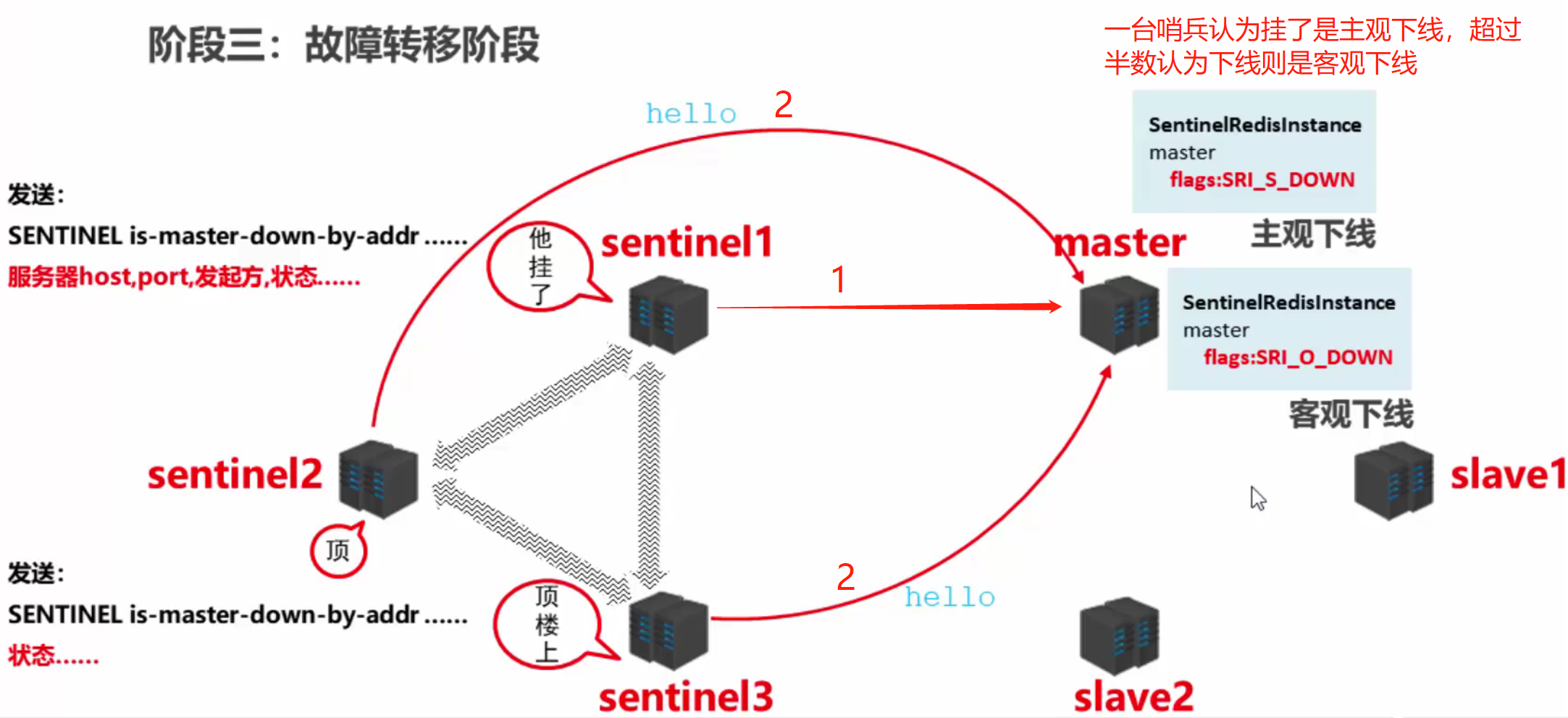
工作原理
sentinel会先向master和slave要信息,要完以后建立一个cmd连接。而sentinel之间会组件一个频道,在里面发布订阅信息,如当master记录了第一个sentinel的信息时,第二个sentinel再发info给master就会发现,它会加入那个频道并将自己的信息发布进去。这样新增哨兵就会快速同步给其他原有哨兵。
当确认主机挂了以后,哨兵会进行选举来确定谁去选新的主机。而每个哨兵都是竞选者也是投票者。具体原理百度即可。
当未来原master重新连接上了,它也依然是从机。
集群
而每一个区域,36-41那部分则是一个个的存储槽,每个计算机中都记录了所有机器的槽的位置。当key访问一台机器没找到时,则会让key去对应槽的机器上寻找。
然而槽的总数是不会发生变化的,每次新增一个节点就只是将当前所有机器中的槽拆出来部分给新的节点
配置文件
线上的时候,节点服务响应超时时间一般设置为30-60s之间
而作为集群启动后,redis-cli就需要加 -c 来专门作为集群方式操作,不加c操作key就必须去对应槽的机器中才能操作
而如果运行过程中如果从机挂了,对应的主机会进行记录(一主对一从时),如果主机挂了,从机会作为新的主机继续运行。而原来的master再上线就只能作为从机运行了。
监控指标